defbalanced_packing(weight:torch.Tensor,num_packs:int)->Tuple[torch.Tensor,torch.Tensor]:"""
Pack n weighted objects to m packs, such that each bin contains exactly n/m objects and the weights of all packs
are as balanced as possible.
Parameters:
weight: [X, n], the weight of each item
num_packs: number of packs
Returns:
pack_index: [X, n], the pack index of each item
rank_in_pack: [X, n], the rank of the item in the pack
"""num_layers,num_groups=weight.shapeassertnum_groups%num_packs==0groups_per_pack=num_groups//num_packsifgroups_per_pack==1:pack_index=torch.arange(weight.size(-1),dtype=torch.int64,device=weight.device).expand(weight.shape)rank_in_pack=torch.zeros_like(weight,dtype=torch.int64)returnpack_index,rank_in_packindices=weight.float().sort(-1,descending=True).indices.cpu()pack_index=torch.full_like(weight,fill_value=-1,dtype=torch.int64,device='cpu')rank_in_pack=torch.full_like(pack_index,fill_value=-1)foriinrange(num_layers):pack_weights=[0]*num_packspack_items=[0]*num_packsforgroupinindices[i]:pack=min((iforiinrange(num_packs)ifpack_items[i]<groups_per_pack),key=pack_weights.__getitem__)assertpack_items[pack]<groups_per_packpack_index[i,group]=packrank_in_pack[i,group]=pack_items[pack]pack_weights[pack]+=weight[i,group]pack_items[pack]+=1returnpack_index,rank_in_packdefreplicate_experts(weight:torch.Tensor,num_phy:int)->Tuple[torch.Tensor,torch.Tensor,torch.Tensor]:"""
Replicate `num_log` experts to `num_phy` replicas, such that the maximum load of all replicas is minimized.
Parameters:
weight: [X, num_log]
num_phy: total number of experts after replication
Returns:
phy2log: [X, num_phy], logical expert id of each physical expert
rank: [X, num_phy], the replica rank
logcnt: [X, num_log], number of replicas for each logical expert
"""n,num_log=weight.shapenum_redundant=num_phy-num_logassertnum_redundant>=0device=weight.devicephy2log=torch.arange(num_phy,dtype=torch.int64,device=device).repeat(n,1)rank=torch.zeros(n,num_phy,dtype=torch.int64,device=device)logcnt=torch.ones(n,num_log,dtype=torch.int64,device=device)arangen=torch.arange(n,dtype=torch.int64,device=device)foriinrange(num_log,num_phy):redundant_indices=(weight/logcnt).max(dim=-1).indicesphy2log[:,i]=redundant_indicesrank[:,i]=logcnt[arangen,redundant_indices]logcnt[arangen,redundant_indices]+=1returnphy2log,rank,logcnt
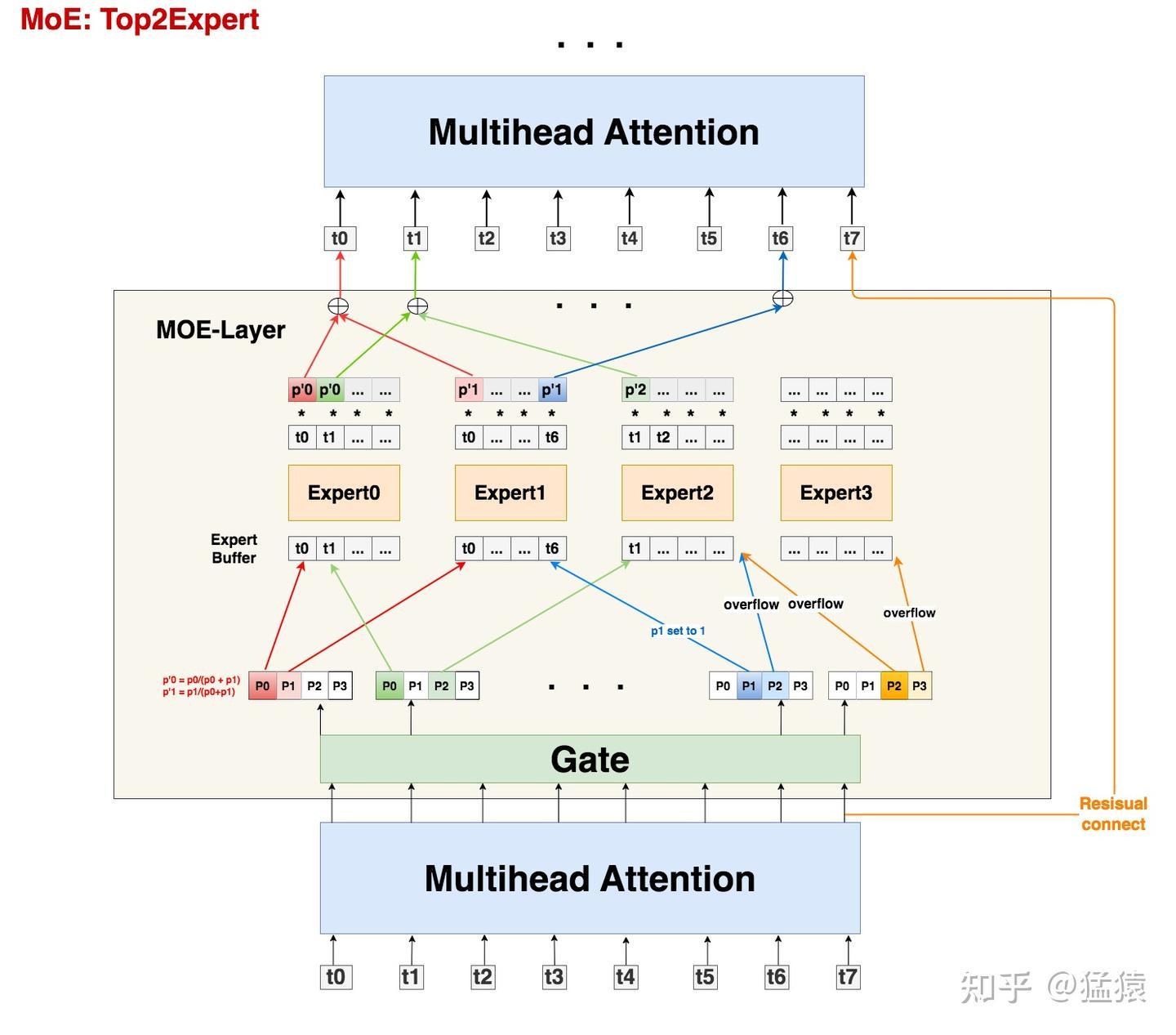
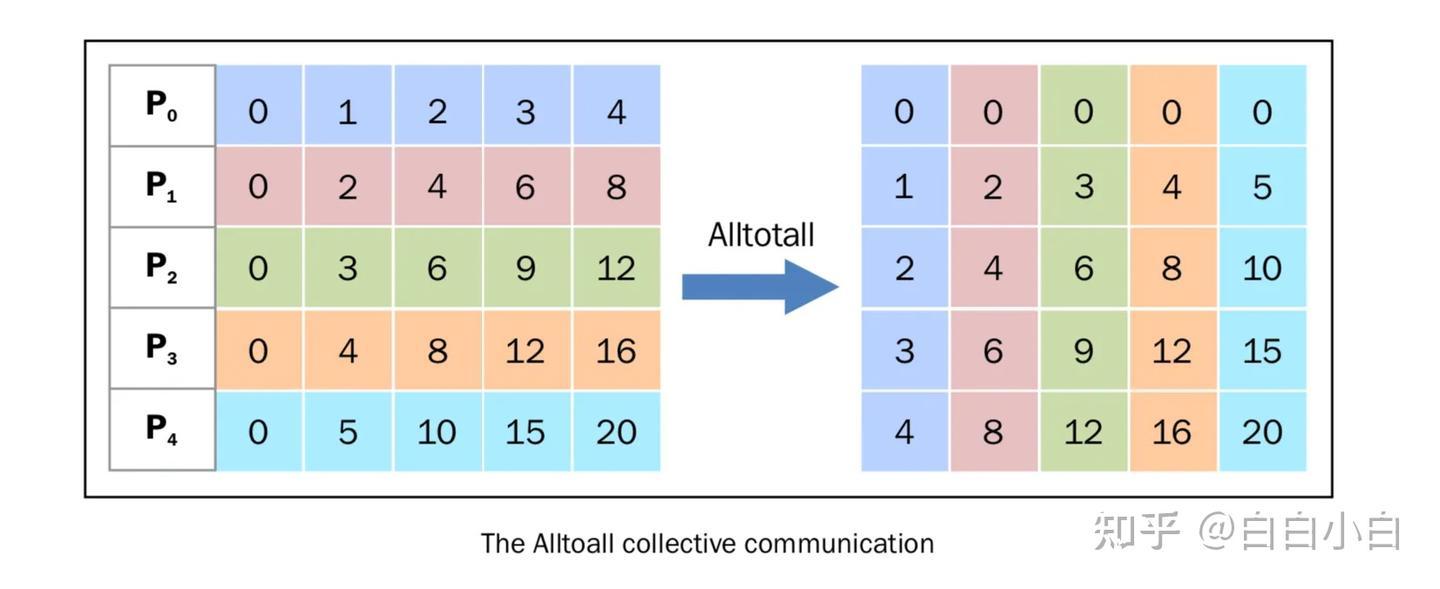
# 分层均衡defrebalance_experts_hierarchical(weight:torch.Tensor,num_physical_experts:int,num_groups:int,num_nodes:int,num_gpus:int):"""
Parameters:
weight: [num_moe_layers, num_logical_experts]
num_physical_experts: number of physical experts after replication
num_groups: number of expert groups
num_nodes: number of server nodes, where the intra-node network (e.g, NVLink) is faster
num_gpus: number of GPUs, must be a multiple of `num_nodes`
Returns:
physical_to_logical_map: [num_moe_layers, num_physical_experts]
logical_to_physical_map: [num_moe_layers, num_logical_experts, X]
logical_count: [num_moe_layers, num_logical_experts]
"""num_layers,num_logical_experts=weight.shapeassertnum_logical_experts%num_groups==0group_size=num_logical_experts//num_groupsassertnum_groups%num_nodes==0groups_per_node=num_groups//num_nodesassertnum_gpus%num_nodes==0assertnum_physical_experts%num_gpus==0phy_experts_per_gpu=num_physical_experts//num_gpusdefinverse(perm:torch.Tensor)->torch.Tensor:inv=torch.empty_like(perm)inv.scatter_(1,perm,torch.arange(perm.size(1),dtype=torch.int64,device=perm.device).expand(perm.shape))returninv# Step 1: 将专家组均匀分配到各个节点,确保不同节点的负载平衡# 将权重矩阵按组进行展开并计算每组的总负载tokens_per_group=weight.unflatten(-1,(num_groups,group_size)).sum(-1)# 使用 balanced_packing 函数将专家组打包到节点上,# 得到每个组所在的节点索引和在该节点内的排名group_pack_index,group_rank_in_pack=balanced_packing(tokens_per_group,num_nodes)# 计算逻辑专家到中间逻辑专家的映射log2mlog=(((group_pack_index*groups_per_node+group_rank_in_pack)*group_size).unsqueeze(-1)+torch.arange(group_size,dtype=torch.int64,device=group_pack_index.device)).flatten(-2)# 计算中间逻辑专家到逻辑专家的逆映射mlog2log=inverse(log2mlog)# Step 2: 在每个节点内复制专家,以最小化所有副本的最大负载。# [num_layers * num_nodes, num_logical_experts // num_nodes]# 根据中间逻辑专家到逻辑专家的映射,重新排列权重矩阵,并按节点进行分组tokens_per_mlog=weight.gather(-1,mlog2log).view(-1,num_logical_experts//num_nodes)# 使用 replicate_experts 函数在每个节点内复制专家,# 得到物理专家到中间逻辑专家的映射、物理专家的排名和每个中间逻辑专家的副本数phy2mlog,phyrank,mlogcnt=replicate_experts(tokens_per_mlog,num_physical_experts//num_nodes)# Step 3: 将复制后的专家分配到各个 GPU 上,确保不同 GPU 的负载平衡。# [num_layers * num_nodes, num_physical_experts // num_nodes]# 计算每个物理专家的负载tokens_per_phy=(tokens_per_mlog/mlogcnt).gather(-1,phy2mlog)# 使用 balanced_packing 函数将物理专家打包到每个节点内的 GPU 上,# 得到每个物理专家所在的 GPU 索引和在该 GPU 内的排名pack_index,rank_in_pack=balanced_packing(tokens_per_phy,num_gpus//num_nodes)# 计算物理专家到最终物理专家的映射phy2pphy=pack_index*phy_experts_per_gpu+rank_in_pack# 计算最终物理专家到物理专家的逆映射pphy2phy=inverse(phy2pphy)# 根据最终物理专家到物理专家的映射,重新排列物理专家到中间逻辑专家的映射pphy2mlog=phy2mlog.gather(-1,pphy2phy)# [num_layers * num_nodes, num_log_per_nodes]# 调整 pphy2mlog 的形状,使其包含所有节点的信息pphy2mlog=(pphy2mlog.view(num_layers,num_nodes,-1)+torch.arange(0,num_logical_experts,num_logical_experts//num_nodes).view(1,-1,1)).flatten(-2)# 根据中间逻辑专家到逻辑专家的映射,将 pphy2mlog 转换为最终物理专家到逻辑专家的映射 pphy2log=mlog2log.gather(-1,pphy2mlog)# 根据最终物理专家到物理专家的映射,重新排列物理专家的排名pphyrank=phyrank.gather(-1,pphy2phy).view(num_layers,-1)# 根据逻辑专家到中间逻辑专家的映射,计算每个逻辑专家的副本数logcnt=mlogcnt.view(num_layers,-1).gather(-1,log2mlog)returnpphy2log,pphyrank,logcnt# 全局均衡(适用于推理时更高的专家并行度)defrebalance_experts(weight:torch.Tensor,num_replicas:int,num_groups:int,num_nodes:int,num_gpus:int)->Tuple[torch.Tensor,torch.Tensor,torch.Tensor]:"""
Entry point for expert-parallelism load balancer.
Parameters:
weight: [layers, num_logical_experts], the load statistics for all logical experts
num_replicas: number of physical experts, must be a multiple of `num_gpus`
num_groups: number of expert groups
num_nodes: number of server nodes, where the intra-node network (e.g, NVLink) is faster
num_gpus: number of GPUs, must be a multiple of `num_nodes`
Returns:
physical_to_logical_map: [layers, num_replicas], the expert index of each replica
logical_to_physical_map: [layers, num_logical_experts, X], the replica indices for each expert
expert_count: [layers, num_logical_experts], number of physical replicas for each logical expert
"""num_layers,num_logical_experts=weight.shapeweight=weight.float().cpu()ifnum_groups%num_nodes==0:# use hierarchical load-balance policyphy2log,phyrank,logcnt=rebalance_experts_hierarchical(weight,num_replicas,num_groups,num_nodes,num_gpus)else:# use global load-balance policyphy2log,phyrank,logcnt=rebalance_experts_hierarchical(weight,num_replicas,1,1,num_gpus)maxlogcnt=logcnt.max().item()log2phy:torch.Tensor=torch.full((num_layers,num_logical_experts,maxlogcnt),-1,dtype=torch.int64,device=logcnt.device)log2phy.view(num_layers,-1).scatter_(-1,phy2log*maxlogcnt+phyrank,torch.arange(num_replicas,dtype=torch.int64,device=log2phy.device).expand(num_layers,-1))returnphy2log,log2phy,logcnt
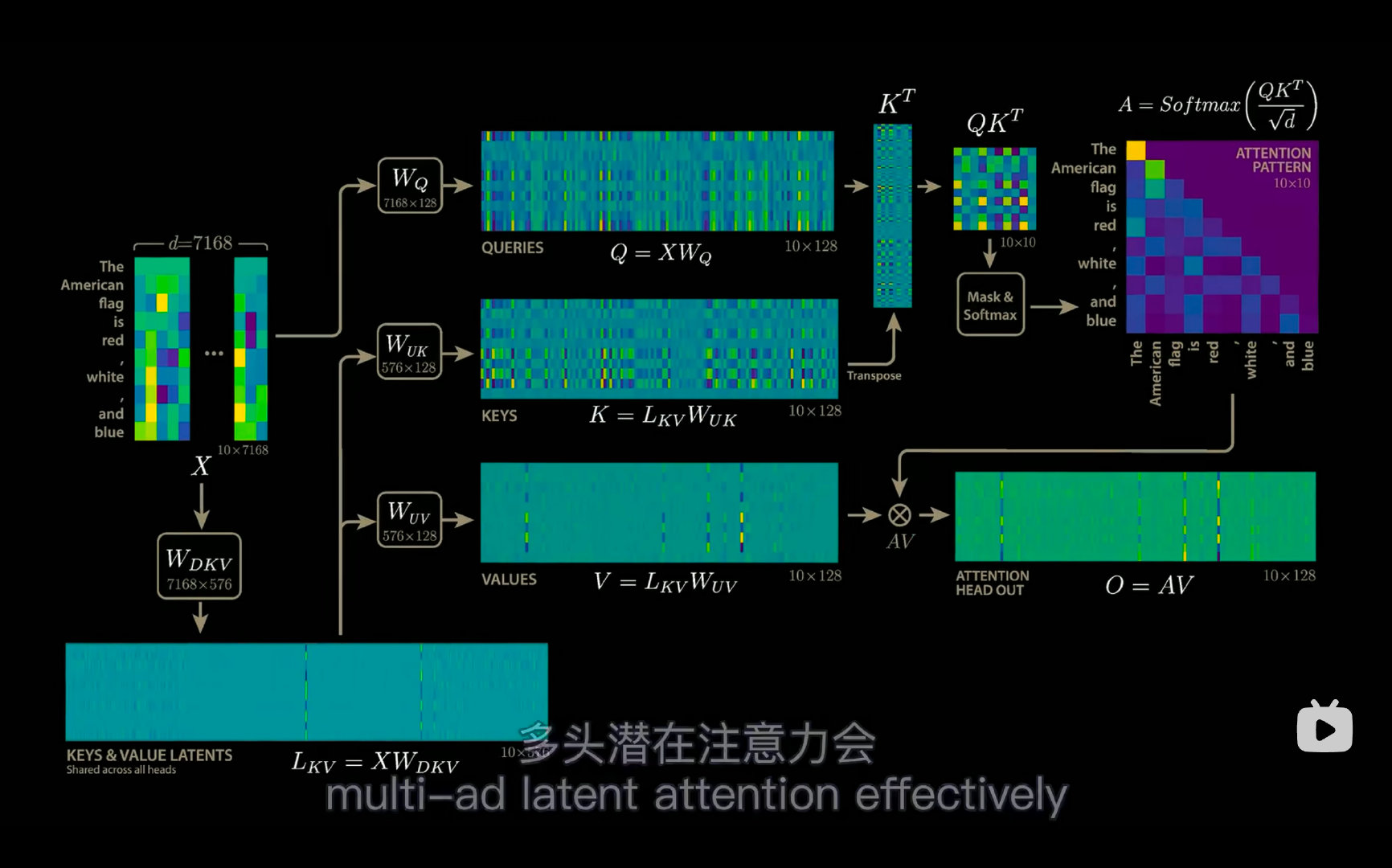
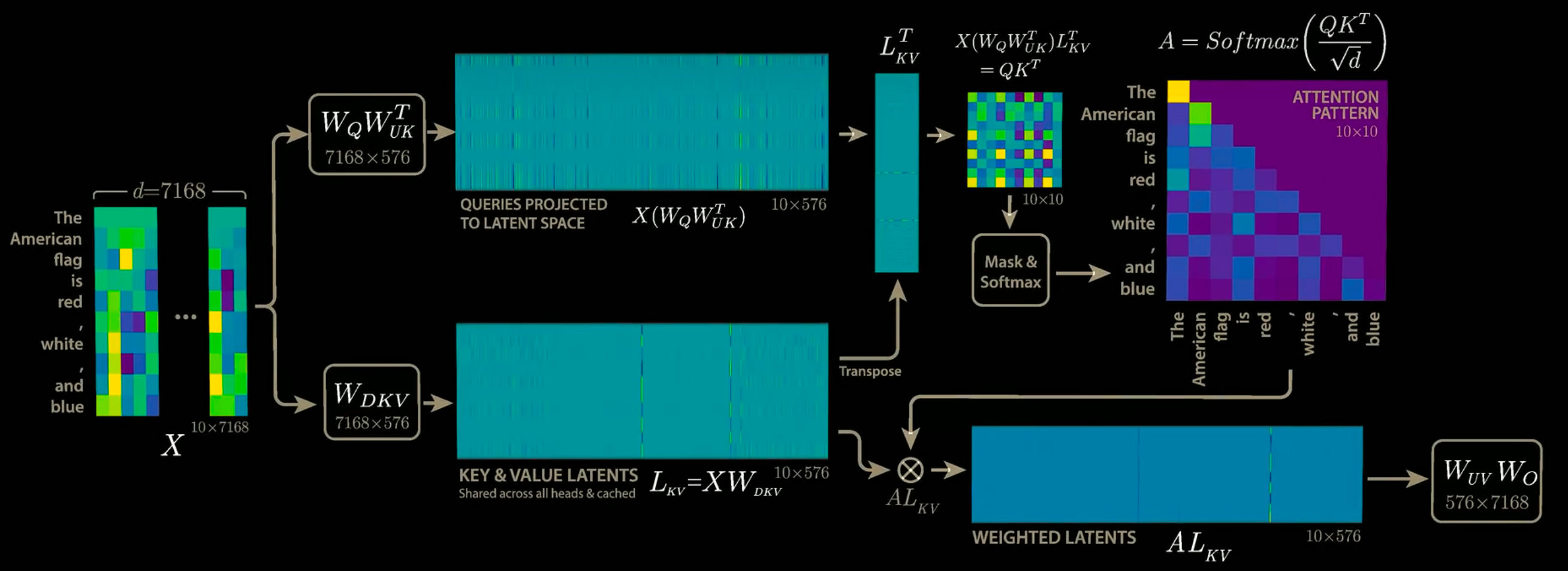
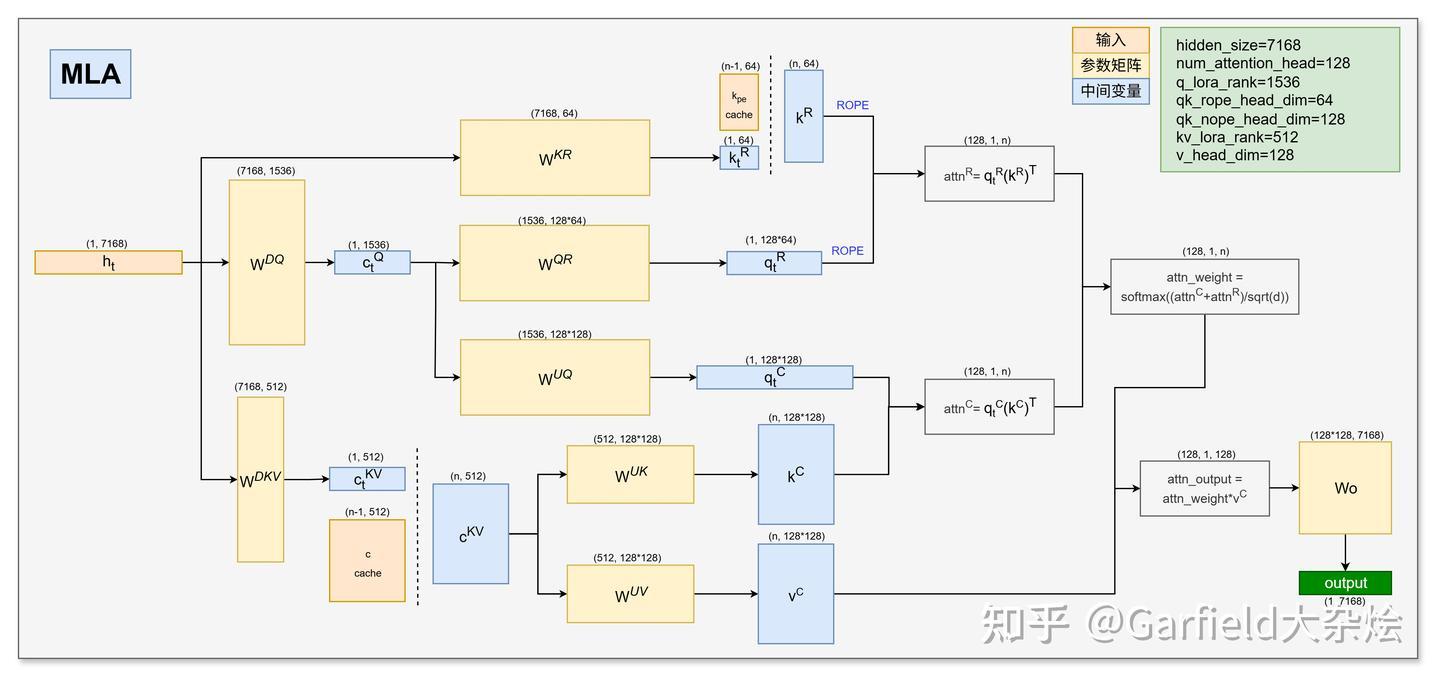
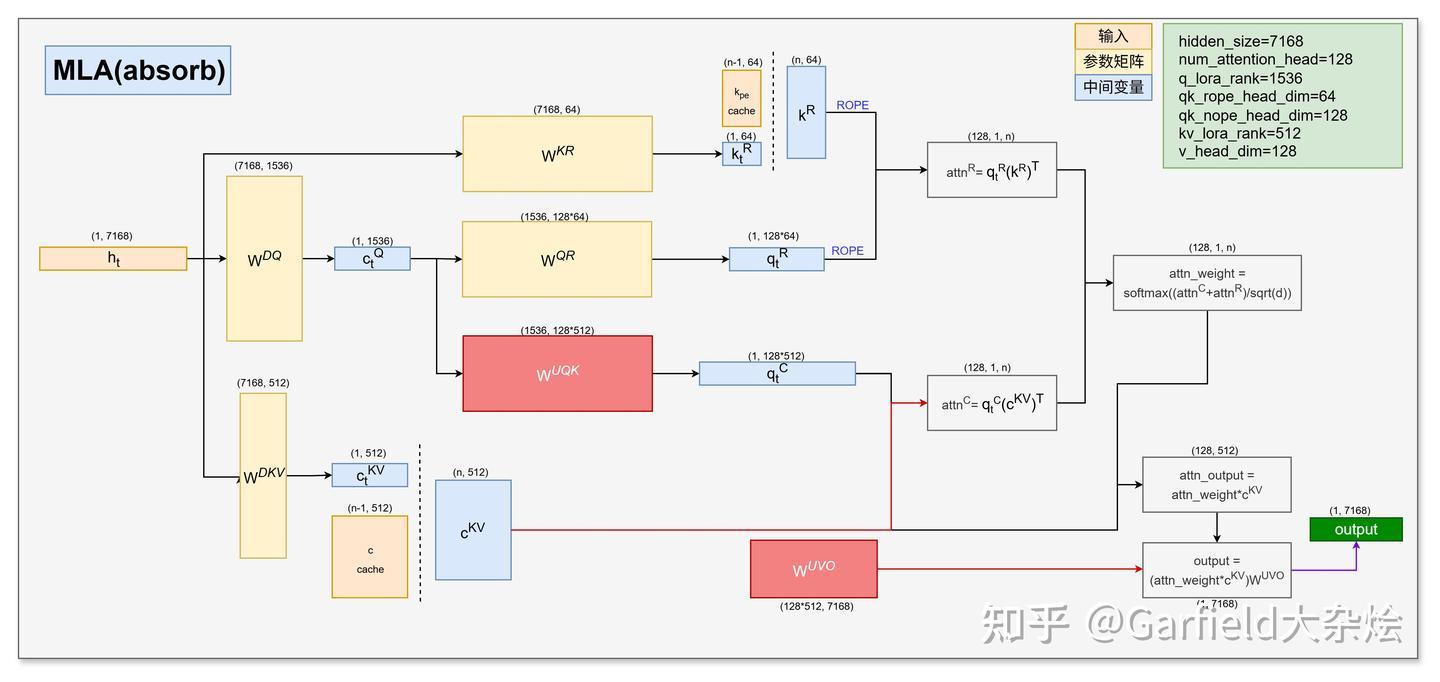
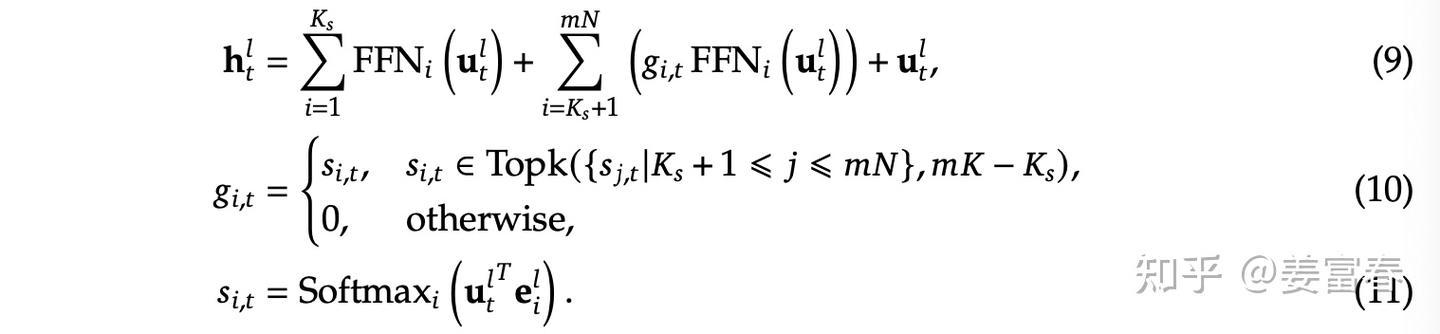
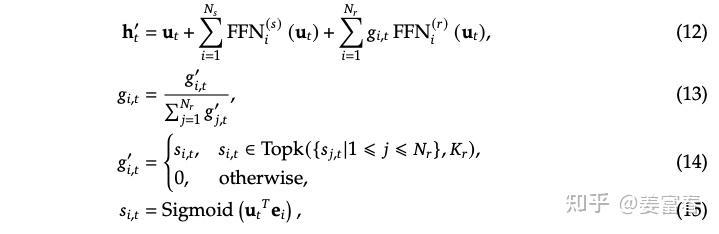

 支付宝
支付宝 微信
微信