《现代C++并发编程教程》 —— C++并发编程学习笔记(一)
启动线程
1
2
3
4
5
6
7
8
9
10
11
| #include <iostream>
#include <thread>
void hello() {
printf("hello world!\n");
}
int main() {
std::thread my_thread(hello);
}
|
可以传入函数对象,如上例所示。也可以传入类或者其他重载了 () (callable)运算符的对象,例如:
1
2
3
4
5
6
7
8
9
10
| class task {
public:
void operator()() const {
do_something();
do_something_else();
}
};
task f;
std::thread my_thread(f);
|
但这里需要注意一个问题,由于 C++ 的语法问题,有时会造成歧义,例如:
1
| std::thread my_thread(task()); // 这会被认为是声明了一个返回值为 thread 的,名为 my_thread 的函数
|
这里最好使用 {} 运算符来创建一个 thread 对象,如: std::thread my_thread{task()}。同时也可以用匿名函数(lambda表达式)来创建线程:
1
2
3
4
5
6
7
| #include <iostream>
#include <thread>
int main() {
std::thread thread{ [] {std::cout << "Hello World!\n"; } };
thread.join();
}
|
当一个线程对象创建时(即 std::thread 对象构造时)就开始执行传入的函数 f 了。
线程管理
启动线程后(构造 std::thread 对象),我们必须在线程的生命周期结束之前,即 std::thread::~thread 调用之前,决定它的执行策略,包括 join() 和 detach()。
join()
其中 join() 表示将阻塞关联的线程,直至执行完毕。内部实现会让 std::thread::joinable() 返回 false。否则会返回 true,执行 std::terminate()。
join()函数是一个等待线程完成函数,主线程需要等待子线程运行结束了才可以结束:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| #include <iostream>
#include <thread>
using namespace std;
void func() {
for(int i = -10; i > -20; i--)
{
cout << "from func():" << i << endl;
}
}
int main() { //主线程
cout << "mian()" << endl;
cout << "mian()" << endl;
cout << "mian()" << endl;
thread t(func); //子线程
t.join(); //等待子线程结束后才进入主线程
return 0;
}
|
detach()
执行了 detach() 后,表示线程对象放弃了对线程资源的所有权,允许此线程的独立运行,在线程退出时释放所有分配的资源。通常不建议使用 detach(),可以用 join() 替代。
使用detach()函数会让线程在后台运行,即说明主线程不会等待子线程运行结束才结束。
可以提供一个类,RAII(Resource Acquisition Initilization)地确保线程执行完成,线程对象正常析构释放资源:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| class thread_guard {
std::thread& m_t;
public:
explicit thread_guard(std::thread& t) : m_t{ t } {}
~thread_guard() {
std::puts("析构"); // 打印日志 不用在乎
if (m_t.joinable()) { // 线程对象当前关联了活跃线程
m_t.join();
}
}
thread_guard(const thread_guard&) = delete;
thread_guard& operator=(const thread_guard&) = delete;
};
void f() {
int n = 0;
std::thread t{ func{n},10 };
thread_guard g(t);
f2(); // 可能抛出异常
}
|
传递参数
向可调用对象传递参数,只需要将这些参数作为 std::thread 的构造参数即可。
需要注意的是,这些参数会复制到新线程的内存空间中,即使函数中的参数是引用,依然实际是复制。
1
2
3
4
| void f(int, const int& a);
int n = 1;
std::thread t{ f, 3, n };
|
线程对象 t 的构造没有问题,可以通过编译,但是这个 n 实际上并没有按引用传递,而是按值复制的。如果我们的 f 的形参类型不是 const 的引用,则会产生一个编译错误。可以用标准库的 std::ref、std::cref 函数模版。
1
2
3
4
5
6
7
8
9
10
| void f(int, int& a) {
std::cout << &a << '\n';
}
int main() {
int n = 1;
std::cout << &n << '\n';
std::thread t { f, 3, std::ref(n) };
t.join();
}
|
共享数据
我们都知道线程通信的方式有临界区、互斥量、信号量、条件变量、读写锁:
- 临界区:每个线程中访问临界资源的那段代码称为临界区(Critical Section)(临界资源是一次仅允许一个线程使用的共享资源)。每次只准许一个线程进入临界区,进入后不允许其他线程进入。不论是硬件临界资源,还是软件临界资源,多个线程必须互斥地对它进行访问。在临界区中,通常会使用同步机制,比如我们要讲的互斥量(Mutex)
- 互斥量:采用互斥对象机制,只有拥有互斥对象的线程才可以访问。因为互斥对象只有一个,所以可以保证公共资源不会被多个线程同时访问。
- 信号量:计数器,允许多个线程同时访问同一个资源。
- 条件变量:通过条件变量通知操作的方式来保持多线程同步。
- 读写锁:读写锁与互斥量类似。但互斥量要么是锁住状态,要么就是不加锁状态。读写锁一次只允许一个线程写,但允许一次多个线程读,这样效率就比互斥锁要高。
如果有以下情况,出现数据竞争情况。
1
2
3
4
5
6
7
8
9
10
11
12
| std::vector<int> v;
void f() { v.emplace_back(1); }
void f2() { v.erase(v.begin()); }
int main() {
std::thread t{ f };
std::thread t2{ f2 };
t.join();
t2.join();
std::cout << v.size() << '\n'; // 有时出现段错误,有时输出0,不稳定的输出结果
}
|
这里我们可以用互斥量来解决这一问题。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| #include <iostream>
#include <mutex>
#include <thread>
#include <vector>
std::mutex m;
std::vector<int> v;
void f() {
m.lock();
v.emplace_back(1);
m.unlock();
}
void f2() {
m.lock();
v.erase(v.begin());
m.unlock();
}
int main() {
std::thread t{ f };
std::thread t2{ f2 };
t.join();
t2.join();
std::cout << v.size() << '\n'; // 稳定输出0
}
|
另外一个例子,使用 mutex 互斥量前:
1
2
3
4
5
6
7
8
9
10
11
12
13
| void f() {
// this_thread::get_id() 表示获取当前线程的唯一标识符,以便在多线程程序中区分不同的线程。
std::cout << std::this_thread::get_id() << '\n';
}
int main() {
std::vector<std::thread> threads;
for (std::size_t i = 0; i < 10; ++i)
threads.emplace_back(f);
for (auto& thread : threads)
thread.join();
}
|
这里有一个点,正好说明一下 push_back() 和 emplace_back() 的区别
- 如果要用
push_back,则需要先构造一个 thread 临时对象:threads.push_back(std::thread(f)); - 而如果用
emplace_back,该方法允许在 vector 末尾直接构造对象,而无需创建临时对象。它接受构造函数的参数,并在适当的位置直接调用构造函数。这样可以减少不必要的对象创建和移动操作,提高性能:threads.emplace_back(f);
std::mutex 和 std::shared_mutex 区别
std::mutex: 独占锁,同一时刻只能有一个线程访问线程资源
std::shared_mutex:读写锁,允许多个线程同时读取,但写入时会独占(C++ 17)引入
使用后:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| #include <mutex> // 必要标头
std::mutex m;
void f() {
m.lock();
std::cout << std::this_thread::get_id() << '\n';
m.unlock();
}
int main() {
std::vector<std::thread>threads;
for (std::size_t i = 0; i < 10; ++i)
threads.emplace_back(f);
for (auto& thread : threads)
thread.join();
}
|
当多个线程执行函数 f 的时候,只有一个线程能成功调用 lock() 给互斥量上锁,其他所有的线程 lock() 的调用将阻塞执行,直至获得锁。第一个调用 lock() 的线程得以继续往下执行,执行我们的 std::cout 输出语句,不会有任何其他的线程打断这个操作。直到线程执行 unlock(),就解锁了互斥量。那么其他线程此时也就能再有一个成功调用 lock。至于是哪个线程才会成功调用,这个是由操作系统调度决定的
这里我理解的是,“锁” 是一种广泛的概念,可以有多种实现方式,c++ 中的互斥量 mutex 可以用来实现锁
std::lock_guard
一般来说,不建议直接使用互斥量 mutex 显式地进行 lock() 和 unlock()。可以用 C++11 标准引入的管理类 std::lock_guard:
1
2
3
4
| void f() {
std::lock_guard<std::mutex> lc{ m }; // 等价于 m.lock(),超出作用域调用析构来 unlock
std::cout << std::this_thread::get_id() << '\n';
}
|
std::lock_guard 实现比较简单,可以看它在 MSVC STL 中的实现。
我们要尽可能的让互斥量上锁的粒度小,只用来确保必须的共享资源的线程安全。
“粒度”通常用于描述锁定的范围大小,较小的粒度意味着锁定的范围更小,因此有更好的性能和更少的竞争。
比如有的时候可以看到这样的写法:
1
2
3
4
5
6
7
8
| void f() {
//code..
{
std::lock_guard<std::mutex> lc{ m };
// 涉及共享资源的修改的代码...
}
//code..
}
|
使用 {} 创建了一个块作用域,限制了对象 lc 的生存期,进入作用域构造 lock_guard 的时候上锁(lock),离开作用域析构的时候解锁(unlock)。
举一个具体的例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| std::mutex m;
void add_to_list(int n, std::list<int>& list) {
std::vector<int> numbers(n + 1);
std::iota(numbers.begin(), numbers.end(), 0); // iota是对vector进行递增(默认递增1)赋值的方法,0是起始值
int sum = std::accumulate(numbers.begin(), numbers.end(), 0); // 0是起始值
{
std::lock_guard<std::mutex> lc{ m };
list.push_back(sum);
}
}
void print_list(const std::list<int>& list){
std::lock_guard<std::mutex> lc{ m };
for(const auto& i : list){
std::cout << i << ' ';
}
std::cout << '\n';
}
// ...... //
std::list<int> list;
std::thread t1{ add_to_list,i,std::ref(list) }; // 上面提到过,传参即使是引用,也会被复制,需要用 std::ref
std::thread t2{ add_to_list,i,std::ref(list) };
std::thread t3{ print_list,std::cref(list) }; // const 引用需要用 std::cref
std::thread t4{ print_list,std::cref(list) };
t1.join();
t2.join();
t3.join();
t4.join();
|
这里的共享数据只有 list, 先看 add_to_list,只有 list.push_back(sum) 涉及到了对共享数据的修改,需要进行保护,因此我们用 {} 包裹。
函数 print_list() 打印 list,给整个函数上锁,同一时刻只能有一个线程执行。我们代码是多个线程执行这两个函数,两个函数共享了一个锁,这样确保了当执行函数 print_list() 打印的时候,list 的状态是确定的。打印函数 print_list 和 add_to_list 函数的修改操作同一时间只能有一个线程在执行。print_list() 不可能看到正在被 add_to_list() 修改的 list。
至于到底哪个函数哪个线程会先执行,执行多少次,这些都由操作系统调度决定,也完全有可能连续 4 次都是执行函数 print_list 的线程成功调用 lock,会打印出了一样的值,这都很正常。
try_lock
try_lock 是互斥量中的一种尝试上锁的方式。与常规的 lock 不同,try_lock 会尝试上锁,但如果锁已经被其他线程占用,则不会阻塞当前线程,而是立即返回。
它的返回类型是 bool ,如果上锁成功就返回 true,失败就返回 false。
这种方法在多线程编程中很有用,特别是在需要保护临界区的同时,又不想线程因为等待锁而阻塞的情况下。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| std::mutex mtx;
void thread_function(int id) {
// 尝试加锁
if (mtx.try_lock()) {
std::cout << "线程:" << id << " 获得锁" << std::endl;
// 临界区代码
std::this_thread::sleep_for(std::chrono::milliseconds(100)); // 模拟临界区操作
mtx.unlock(); // 解锁
std::cout << "线程:" << id << " 释放锁" << std::endl;
} else {
std::cout << "线程:" << id << " 获取锁失败 处理步骤" << std::endl;
}
}
|
如果有两个线程运行这段代码,必然有一个线程无法成功上锁,要走 else 的分支。
1
2
3
4
5
| std::thread t1(thread_function, 1);
std::thread t2(thread_function, 2);
t1.join();
t2.join();
|
可能的运行结果:
1
2
3
| 线程:1 获得锁
线程:2 获取锁失败 处理步骤
线程:1 释放锁
|
小心
切勿将受保护数据的指针或引用传递到互斥量作用域之外,不然保护将形同虚设。下面是一个具体例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| class Data {
int a{};
std::string b{};
public:
void do_something() {
// 修改数据成员等...
}
};
class Data_wrapper {
Data data;
std::mutex m;
public:
template<class Func>
void process_data(Func func) {
std::lock_guard<std::mutex> lc{m};
func(data); // 受保护数据传递给函数
}
};
Data* p = nullptr;
void malicious_function(Data& protected_data) {
p = &protected_data; // 受保护的数据被传递到外部
}
Data_wrapper d;
void foo() {
d.process_data(malicious_function); // 传递了一个恶意的函数
p->do_something(); // 在无保护的情况下访问保护数据
}
|
成员函数模板 process_data 看起来一点问题也没有,使用 std::lock_guard 对数据做了保护,但是调用方传递了 malicious_function 这样一个恶意的函数,使受保护数据传递给外部,可以在没有被互斥量保护的情况下调用 do_something()。
死锁:问题与解决
两个线程需要对它们所有的互斥量做一些操作,其中每个线程都有一个互斥量,且等待另一个线程的互斥量解锁。因为它们都在等待对方释放互斥量,没有线程工作。 这种情况就是死锁。一般只有多个互斥量才会遇到死锁问题
死锁发生的四个必要条件
- 互斥(资源一次只能被一个线程占用)
- 持有且等待(线程已持有资源,并等待其他资源)
- 不可抢占(已持有资源不能被强制释放)
- 循环等待(多个线程互相等待对方释放资源)
避免死锁的一般建议是让两个互斥量以相同的顺序上锁,总在互斥量 B 之前锁住互斥量 A,就通常不会死锁。反面示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
| std::mutex m1,m2;
std::size_t n{};
void f() {
std::lock_guard<std::mutex> lc1{ m1 };
std::lock_guard<std::mutex> lc2{ m2 };
++n;
}
void f2() {
std::lock_guard<std::mutex> lc1{ m2 };
std::lock_guard<std::mutex> lc2{ m1 };
++n;
}
|
f 与 f2 因为互斥量上锁顺序不同,就有死锁风险。函数 f 先锁定 m1,然后再尝试锁定 m2,而函数 f2 先锁定 m2 再锁定 m1 。如果两个线程同时运行,它们就可能(具体获得锁的顺序由操作系统调度决定,上面阐述过)会彼此等待对方释放其所需的锁,从而造成死锁。
但有时候即使固定了锁的顺序,依旧会产生问题。当有多个互斥量保护同一个类的对象时,对于相同类型的两个不同对象进行数据的交换操作,为了保证数据交换的正确性,就要避免其它线程修改,确保每个对象的互斥量都锁住自己要保护的区域。如果按照前面的的选择一个固定的顺序上锁解锁,则毫无意义,比如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| struct X {
X(const std::string& str) :object{ str } {}
friend void swap(X& lhs, X& rhs);
private:
std::string object;
std::mutex m;
};
void swap(X& lhs, X& rhs) {
if (&lhs == &rhs) return;
std::lock_guard<std::mutex> lock1{ lhs.m };
std::lock_guard<std::mutex> lock2{ rhs.m };
swap(lhs.object, rhs.object);
}
|
考虑用户调用的时候将参数交换,就会产生死锁:
1
2
3
| X a{ "🤣" }, b{ "😅" };
std::thread t{ [&] {swap(a, b); } }; // 1
std::thread t2{ [&] {swap(b, a); } }; // 2
|
1 执行的时候,先上锁 a 的互斥量,再上锁 b 的互斥量。
2 执行的时候,先上锁 b 的互斥量,再上锁 a 的互斥量。
完全可能线程 A 执行 1 的时候上锁了 a 的互斥量,线程 B 执行 2 上锁了 b 的互斥量。线程 A 往下执行需要上锁 b 的互斥量,线程 B 则要上锁 a 的互斥量执行完毕才能解锁,哪个都没办法往下执行,死锁。
如何解决?可以使用 C++ 标准库中的 std::lock,它能一次性锁住多个互斥量,并且没有死锁风险。修改后 swap 代码如下:
1
2
3
4
5
6
7
| void swap(X& lhs, X& rhs) {
if (&lhs == &rhs) return;
std::lock(lhs.m, rhs.m); // 给两个互斥量上锁
std::lock_guard<std::mutex> lock1{ lhs.m,std::adopt_lock };
std::lock_guard<std::mutex> lock2{ rhs.m,std::adopt_lock };
swap(lhs.object, rhs.object);
}
|
因为前面已经使用了 std::lock 上锁,所以后面的 std::lock_guard 构造都额外传递了一个 std::adopt_lock 参数,让其选择到不上锁的构造函数。函数退出也能正常解锁。
std::lock 给 lhs.m 或 rhs.m 上锁时若抛出异常,则在重抛前对任何已锁的对象调用 unlock() 解锁,也就是 std::lock 要么将互斥量都上锁,要么一个都不锁。
C++17 新增了 std::scoped_lock ,提供此函数的 RAII 包装,通常它比裸调用 std::lock 更好。
所以我们前面的代码可以改写为:
1
2
3
4
5
| void swap(X& lhs, X& rhs) {
if (&lhs == &rhs) return;
std::scoped_lock guard{ lhs.m,rhs.m };
swap(lhs.object, rhs.object);
}
|
使用 std::scoped_lock 可以将所有 std::lock 替换掉,减少错误发生。也可以用 std::unique_lock(可以简单理解为 std::lock_guard 的升级版,具有额外的功能,为更复杂的锁做准备),详情见标准库文档。
总结,避免死锁要注意:
- 避免嵌套锁:线程获取一个锁时,就别再获取第二个锁。每个线程只持有一个锁,自然不会产生死锁。如果必须要获取多个锁,使用
std::lock。 - 避免在持有锁时调用外部代码
- 使用固定顺序获取锁
读写锁
如果需要多线程读取写(多线程读不存在数据竞争;而写和读共存时存在竞争),使用 std::mutex 开销较大。这时可以用专门的读写锁,即 std::shared_timed_mutex (C++ 14),std::shared_mutex (C++ 17)。示例代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| class Settings {
private:
std::map<std::string, std::string> data_;
mutable std::shared_mutex mutex_; // “M&M 规则”:mutable 与 mutex 一起出现
public:
void set(const std::string& key, const std::string& value) {
std::lock_guard<std::shared_mutex> lock{ mutex_ };
data_[key] = value;
}
std::string get(const std::string& key) const {
std::shared_lock<std::shared_mutex> lock(mutex_);
auto it = data_.find(key);
return (it != data_.end()) ? it->second : ""; // 如果没有找到键返回空字符串
}
};
|
使用互斥量实现并发读写锁(字节 Data AML 一面手撕题)
我们知道,写操作是独占的;而读操作是非独占的,即多个线程可以同时读。如果多线程访问某个共享变量时,每次访问时都加上一个互斥锁,这样开销会非常大。
所以我们期望在多个线程试图读取共享变量的时候,它们可以立刻获取因为读而加的锁,而不是需要等待前一个线程释放。当然,如果一个线程用写锁锁住了临界区,那么其他线程无论是读还是写都会发生阻塞。
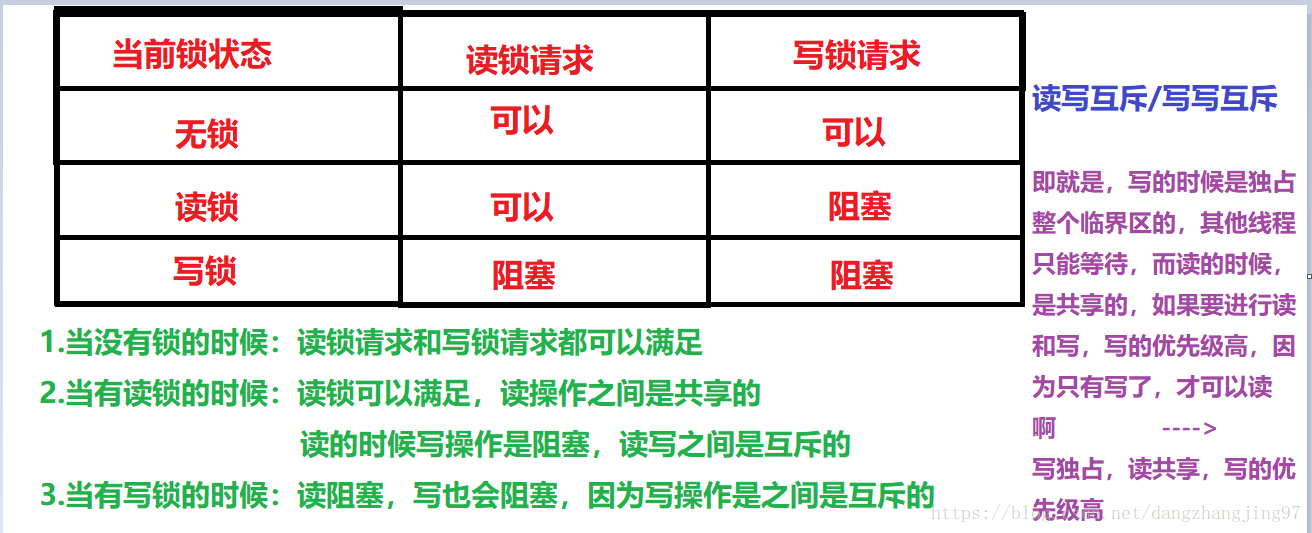
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
| #include <iostream>
#include <mutex>
#include <thread>
class ReadWriteLock {
private:
std::mutex readMutex; // 用于保护读操作计数器的互斥量
std::mutex writeMutex; // 用于保护写操作的互斥量
int readCount = 0; // 记录当前正在进行读操作的线程数量
bool writing = false; // 表示当前是否有线程正在进行写操作
public:
void readLock() {
// 锁定读操作互斥量
std::unique_lock<std::mutex> readLock(readMutex);
// 增加读操作计数器
++ readCount;
// 等待没有写操作时进行读操作
while (writing) {
readLock.unlock();
std::this_thread::yield(); // 让出CPU,避免忙等待
readLock.lock();
}
}
void readUnlock() {
// 锁定读操作互斥量并减少读操作计数器
std::lock_guard<std::mutex> readLock(readMutex);
-- readCount;
}
void writeLock() {
// 锁定写操作互斥量
std::unique_lock<std::mutex> writeLock(writeMutex);
// 等待没有读操作和写操作时进行写操作
while (readCount > 0 || writing) {
writeLock.unlock();
std::this_thread::yield(); // 让出CPU,避免忙等待
writeLock.lock();
}
// 标记正在进行写操作
writing = true;
}
void writeUnlock() {
// 锁定写操作互斥量并标记写操作完成
std::lock_guard<std::mutex> writeLock(writeMutex);
writing = false;
}
};
// 示例使用
int sharedData = 0;
ReadWriteLock lock;
void reader() {
lock.readLock();
std::cout << "Reading: " << sharedData << std::endl;
lock.readUnlock();
}
void writer() {
lock.writeLock();
++ sharedData;
std::cout << "Writing: " << sharedData << std::endl;
lock.writeUnlock();
}
int main() {
std::thread readers[5];
std::thread writers[3];
// 创建多个读线程和写线程
for (int i = 0; i < 5; ++i) {
readers[i] = std::thread(reader);
}
for (int i = 0; i < 3; ++i) {
writers[i] = std::thread(writer);
}
// 等待所有线程执行完毕
for (auto& reader : readers) {
reader.join();
}
for (auto& writer : writers) {
writer.join();
}
return 0;
}
|
这段代码中,锁定操作用的是 std::unique_lock,而解锁操作用的是 std::lock_guard。这两者都是 C++ 11 引入的 RAII 包装。正如上面所述,unique_lock 是 lock_guard 的升级版(更灵活,常与条件变量的 wait()、notify_one()、notify_all()配合使用),这里锁定时需要解锁和重新锁定互斥量。这对于需要在等待条件满足时解锁互斥量并让出 CPU 的场景非常有用。
 支付宝
支付宝 微信
微信