推理引擎请求调度优化
批处理
静态批处理(Static Batching)
请求被放入批处理队列中,当批处理队列满了之后再运行。
静态批处理是批处理请求最简单的实现。但它会大幅增加延迟,从而限制其使用场景。
如果说单独运行每个请求就像每个人开自己的车,那么批处理就像一辆公交车。如果公交车采用静态批处理,司机会等待车内乘客满载,然后开往目的地。这确保了公交车每次行驶时都满载。同样,用于模型推理的静态批处理会等到收到一定数量的请求后,再运行单个批处理来同时处理这些请求。
当对于某个业务流程来说延迟不是问题时,例如每天处理大量文档,静态批处理是最合适的。静态批处理会增加在系统其他位置协调请求的复杂性。使用静态批处理需要一个管理良好的请求队列来为模型提供数据,并且需要一个以大块形式接收模型输出的方法。
动态批处理(Dynamic Batching)
请求在收到时被分批放置到队列中,在队列满了或自第一个请求以来经过足够的时间后进行批处理。
静态批处理非常适合日常作业或后台处理。但对于延迟敏感(这里主要是和用户的交互相关业务场景)的生产部署(例如:根据用户输入生成图像),静态批处理并不适用。
回到我们之前关于公交车的比喻,想象一下,在车流量不大的日子里,你是第一个上车的人。如果你必须等到车上坐满才能出发,那你得等很长时间。但如果司机在第一个乘客上车时启动一个计时器,并在车上坐满或计时器用完(以先到者为准)时出发,那会怎么样呢?这样,你最多只需要等几分钟。
动态批处理的工作方式相同。您可以使用以下命令设置动态批处理:
- 预设的最大批量大小,您希望在每次进行批处理之前达到该大小。
- 在运行部分批处理之前接收第一个请求后等待的窗口。
假设你设置的模型服务器的批处理大小为 16 个请求,窗口为 100 毫秒。当服务器收到第一个请求时,它将:
- 在 100 毫秒内接收 15 个以上请求并立即运行完整批次,或者
- 接收少于 15 个请求,并在 100 毫秒后运行部分批处理。
动态批处理非常适合 Stable Diffusion XL 等模型的实时流量,因为每个推理请求所需的时间大致相同。具体部署的正确设置取决于流量模式和延迟要求,但动态批处理可为您提供多种选项的灵活性。
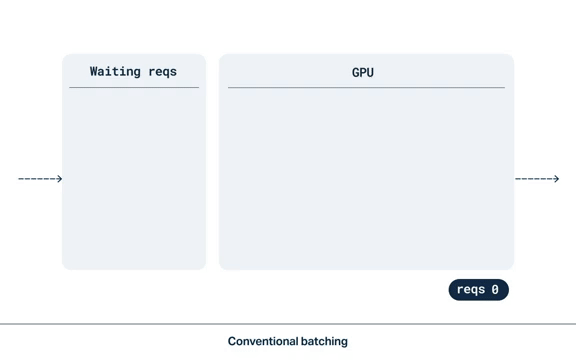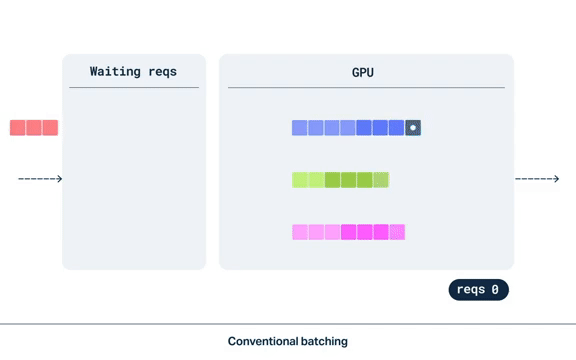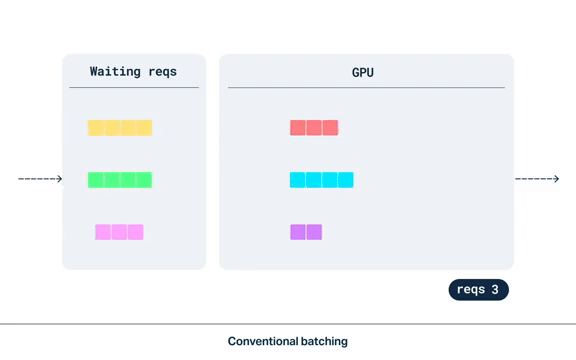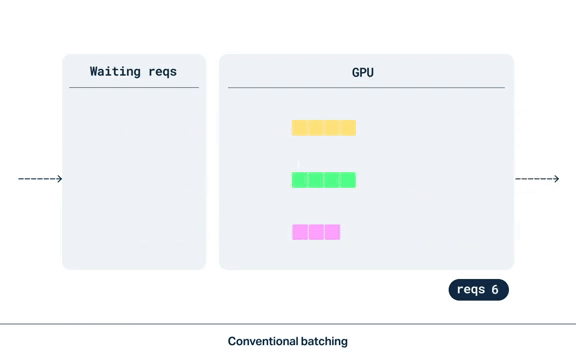
连续批处理(Continuous Batching)
来源于 Orca OSDI'22
请求按令牌逐个进行处理,当旧请求完成并释放 GPU 上的空间时,新请求就会得到处理。
虽然动态批处理非常适合图像生成等场景,其中每个输出大约需要相同的时间来创建,但我们可以通过连续批处理为 LLM 做得更好。
LLM 会创建一系列 token 作为输出。这些输出序列的长度会有所不同——模型可以回答一个简单的问题,也可以通过逐步推理进行详细的分析。如果使用动态批处理方法,则每批请求都需要等待最长的输出完成后才能开始下一批请求。这会导致 GPU 资源闲置。
连续批处理在令牌级别而非请求级别进行。LLM 推理的瓶颈在于模型权重的加载。因此,对于连续批处理,模型服务器会按顺序加载模型的每一层,并将其应用于每个请求的下一个令牌。在连续批处理中,相同的模型权重可用于生成一个响应的第 5 个令牌和另一个响应的第 85 个令牌。
在公交车的例子中,连续批处理类似于现实世界中公交线路的运作方式。当司机沿着路线行驶时,乘客的乘坐时间会有所不同。当一位乘客到达目的地时,就会为另一位乘客腾出座位。
通过消除等待每个批次的最长响应完成的空闲时间,连续批处理比动态批处理提高了 GPU 的利用率。
PD分离
SGL和vllm区别
参考:https://www.zhihu.com/question/666943660/answer/1940915117643530378
MNN
MNN 是一个为移动端和嵌入式设备设计的轻量级深度学习推理引擎。它的核心目标是在资源有限的硬件上,如手机、物联网设备和智能家居,高效地运行神经网络模型。
设计理念: 追求极致的轻量化和高性能。它通过各种优化技术,如量化、模型压缩、算子融合和硬件加速,来减少模型大小、降低内存占用和提升计算速度。
支持模型: 主要用于视觉、语音和传统机器学习任务,例如图像分类、目标检测、人脸识别、风格迁移和语音识别。
优化重点:
异构计算: 充分利用 CPU、GPU 和 DSP 等不同硬件的特性。
内存优化: 采用内存池等技术,减少内存分配和碎片化。
量化技术: 支持 FP32、FP16、Int8 等多种数据类型,以适应不同硬件平台并提升性能。
LLM 推理引擎 专门为大型语言模型设计,如 Llama、GPT 和 Mistral 等。这些模型通常拥有数百亿甚至上万亿的参数,对计算和内存资源的需求极高。
设计理念: 旨在解决 LLM 推理中的独特挑战,包括巨大的模型尺寸、高昂的计算量和 KV 缓存(Key-Value Cache)的内存开销。
支持模型: 专注于处理基于 Transformer 架构的超大规模语言模型。
优化重点:
并行计算: 利用多 GPU 和分布式计算来加载和运行庞大的模型。
KV 缓存管理: 优化注意力机制中的 KV 缓存,以减少内存占用并提升推理速度。
FlashAttention 等高效算法: 采用专门为 Transformer 设计的优化算法,以减少显存访问并提升计算效率。
量化和剪枝: 虽然 MNN 也使用这些技术,但 LLM 推理引擎中的量化通常更复杂,需要确保量化后模型的性能损失最小。
动态批处理: 动态地调整批处理大小,以最大化 GPU 利用率。
计算图
什么是计算图?
首先,计算图是一种有向无环图(DAG, Directed Acyclic Graph),它用来描述运算操作之间的关系。在图中:
节点(Nodes) 代表数据(张量 Tensor)或者操作(Operations)。
边(Edges) 代表数据流向,表示数据从一个操作传递到另一个操作。
举一个最简单的例子,假设我们有这样一个数学表达式: y = (a + b) * c
这个表达式可以用如下的计算图来表示:
PyTorch 计算图的核心特点:动态性
这是 PyTorch 与 TensorFlow 1.x 等早期框架最显著的区别。
静态图 (Static Graph - 如 TensorFlow 1.x):
定义与运行分离 (Define-and-Run)。 你需要先完整地定义好整个计算图的结构,然后才能向这个固定的图中输入数据并执行它。
优点: 可以在运行前对整个图进行优化,例如分配显存、融合算子,因此潜在的性能可能更高。
缺点: 不够灵活。对于需要根据输入数据动态改变计算流程的模型(如循环神经网络 RNN 中处理不同长度的序列),定义起来非常麻烦和不直观。
动态图 (Dynamic Graph - PyTorch):
定义与运行合一 (Define-by-Run)。 计算图是在代码运行时动态生成的。每当你执行一个操作,一个新的节点和相应的边就被添加到图中。
优点:
直观灵活: 代码所见即所得,你可以像写普通 Python 程序一样使用 if/else、for 循环等控制流语句,计算图会根据你的执行路径自然地构建出来。这使得调试非常方便。
易于处理动态输入: 对于 RNN 等模型极为友好。
缺点: 理论上,由于图是动态生成的,难以进行全局优化,可能会有一些性能开销。但随着 PyTorch 的发展(如 torch.jit.script 和 TorchDynamo),这个差距正在被不断缩小。
PyTorch 计算图是如何构建的?
PyTorch 的计算图是在前向传播(Forward Pass) 过程中,由 autograd 系统自动构建的。这个图记录了所有张量以及对它们进行的操作历史。
我们来看关键的几个组件:
torch.Tensor: 这是图中的核心数据结构。一个张量有几个重要属性:
data: 存储张量的实际数据。
requires_grad: 一个布尔值。如果为 True,表示该张量需要计算梯度。autograd 系统会从这个张量开始追踪所有操作。通常,模型的权重参数该值为 True,而输入数据默认为 False。
grad: 存储计算出的梯度值。初始时为 None。
grad_fn: 这是构建计算图的关键! 它引用了一个 Function 对象,该对象记录了创建这个张量的操作。如果一个张量是用户直接创建的(叶子节点),那么它的 grad_fn 为 None。
计算图如何用于反向传播?
计算图最重要的作用就是为了计算梯度。当你对某个张量(通常是最终的损失 loss)调用 .backward() 方法时,autograd 引擎就会启动。
过程如下:
启动: 从调用 .backward() 的张量(例如 y)开始,传入一个初始梯度(对于标量,默认为 1.0)。
反向遍历: autograd 引擎沿着计算图,从根节点 y 向叶子节点 a, b, c 反向传播。
链式法则: 在每个节点处,autograd 会使用该节点的 grad_fn 来计算输入张量相对于当前节点的梯度。这本质上就是应用微积分中的链式法则。
例如,在 y 节点,autograd 计算 y 对 d 和 c 的偏导数。
然后传播到 d 节点,autograd 计算 d 对 a 和 b 的偏导数。
梯度累积: 计算出的梯度会被**累积(accumulate)**到各个叶子节点的 .grad 属性中。这就是为什么在每个训练迭代开始时,我们通常需要调用 optimizer.zero_grad(),否则梯度会一直叠加。
 支付宝
支付宝 微信
微信