《现代C++并发编程教程》 —— C++并发编程学习笔记(三)
原子操作
1
2
3
4
int a = 0 ;
void f () {
++ a ;
}
显然,++a 是非原子操作,也就是说在多线程中可能会被另一个线程观察到只完成一半。
可以用互斥量来保护共享资源:
1
2
3
4
5
std :: mutex m ;
void f () {
std :: lock_guard < std :: mutex > lc { m };
++ a ;
}
通过互斥量的保护,即使 ++a 本身不是原子操作,逻辑上也可视为原子操作。互斥量确保了对共享资源的读写是线程安全的,避免了数据竞争问题。
不过这显然不是我们的重点。我们想要的是一种原子类型,它的所有操作都直接是原子的,不需要额外的同步设施进行保护。C++11 引入了原子类型 std::atomic。
原子类型
这里只简单介绍 std::atomic<bool>(包含在 <atomic> 中),最基本的整数原子类型。虽然同样不可复制不可移动,但可以使用非原子的 bool 类型进行构造,初始化为 true 或 false,并且能从非原子的 bool 对象赋值给 std::atomic<bool>:
1
2
std :: atomic < bool > b { true };
b = false ;
这些类型的操作都是原子的,语言定义中只有这些类型的操作是原子的,虽然也可以用互斥量来模拟原子操作。
线程池
抽象的来说,可以当做是一个池子中存放了一堆线程,故称作线程池 。简而言之,线程池是指代一组预先创建的、可以复用的线程集合 。这些线程由线程池管理,用于执行多个任务而无需频繁地创建和销毁 线程。
这是一个典型的线程池结构。线程池包含一个任务队列,当有新任务加入时,调度器会将任务分配给线程池中的空闲线程进行执行。线程在执行完任务后会进入休眠状态,等待调度器的下一次唤醒。当有新的任务加入队列,并且有线程处于休眠状态时,调度器会唤醒休眠的线程,并分配新的任务给它们执行。线程执行完新任务后,会再次进入休眠状态,直到有新的任务到来,调度器才可能会再次唤醒它们。
图中线程1 就是被调度器分配了任务1,执行完毕后休眠,然而新任务的到来让调度器再次将它唤醒,去执行任务6,执行完毕后继续休眠。
使用线程池的益处我们已经加粗了,然而这其实并不是“线程池”独有的,任何创建和销毁存在较大开销的设施,都可以进行所谓的“池化”。
常见的还有:套接字连接池、数据库连接池、内存池、对象池 。
下面简单介绍下常用的线程池。
boost::asio::thread_poolboost::asio::thread_pool 是 Boost.Asio 库提供的一种线程池实现。
Asio 是一个跨平台的 C++ 库,用于网络和低级 I/O 编程,使用 现代C++ 方法为开发人员提供一致的异步模型。
使用方法:
创建线程池对象,指定或让 Asio 自动决定线程数量。 提交任务:通过 boost::asio::post 函数模板提交任务到线程池中。 阻塞,直到池中的线程完成任务。 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#include <boost/asio.hpp>
#include <iostream>
std :: mutex m ;
void print_task ( int n ) {
std :: lock_guard < std :: mutex > lc { m };
std :: cout << "Task " << n << " is running on thr: " <<
std :: this_thread :: get_id () << '\n' ;
}
int main () {
boost :: asio :: thread_pool pool { 4 }; // 创建一个包含 4 个线程的线程池
for ( int i = 0 ; i < 10 ; ++ i ) {
boost :: asio :: post ( pool , [ i ] { print_task ( i ); });
}
pool . join (); // 等待所有任务执行完成
}
详情见 boost/asio 的使用,这里不再展开。
实现线程池
实现一个普通的能够满足日常开发需求的线程池实际上非常简单,只需要不到一百行代码。其实绝大部分开发者使用线程池,只是为了不重复多次创建线程罢了。所以只需要一个提供一个外部接口,可以传入任务到任务队列,然后安排线程去执行。无非是使用条件变量、互斥量、原子标志位,这些东西,就足够编写一个满足绝大部分业务需求的线程池。
我们先编写一个最基础的线程池,首先确定它的数据成员:
1
2
3
4
5
6
7
8
class ThreadPool {
std :: mutex mutex_ ; // 用于保护共享资源(如任务队列)在多线程环境中的访问,避免数据竞争。
std :: condition_variable cv_ ; // 用于线程间的同步,允许线程等待特定条件(如新任务加入队列)并在条件满足时唤醒线程。
std :: atomic < bool > stop_ ; // 指示线程池是否停止。
std :: atomic < std :: size_t > num_threads_ ; // 表示线程池中的线程数量。
std :: queue < Task > tasks_ ; // 任务队列,存储等待执行的任务,任务按提交顺序执行。
std :: vector < std :: thread > pool_ ; // 线程容器,存储管理线程对象,每个线程从任务队列中获取任务并执行。
};
标头依赖:
1
2
3
4
5
6
7
8
9
10
#include <iostream>
#include <thread>
#include <mutex>
#include <condition_variable>
#include <future>
#include <atomic>
#include <queue>
#include <vector>
#include <syncstream>
#include <functional>
提供构造析构函数,以及一些外部接口:submit()、start()、stop()、join(),也就完成了:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
inline std :: size_t default_thread_pool_size () noexcept {
std :: size_t num_threads = std :: thread :: hardware_concurrency () * 2 ;
num_threads = num_threads == 0 ? 2 : num_threads ;
return num_threads ;
}
class ThreadPool {
private :
std :: mutex mutex_ ;
std :: condition_variable cv_ ;
std :: atomic < bool > stop_ ;
std :: atomic < std :: size_t > num_threads_ ;
std :: queue < Task > tasks_ ;
std :: vector < std :: thread > pool_ ;
public :
using Task = std :: packaged_task < void () > ;
ThreadPool ( const ThreadPool & ) = delete ;
ThreadPool & operator = ( const ThreadPool & ) = delete ;
ThreadPool ( std :: size_t num_thread = default_thread_pool_size ())
: stop_ { false }, num_threads_ { num_thread } {
start ();
}
~ ThreadPool () {
stop ();
}
void stop () {
stop_ . store ( true );
cv_ . notify_all ();
for ( auto & thread : pool_ ) {
if ( thread . joinable ()) {
thread . join ();
}
}
pool_ . clear ();
}
template < typename F , typename ... Args >
std :: future < std :: invoke_result_t < std :: decay_t < F > , std :: decay_t < Args > ... >> submit ( F && f , Args && ... args ) {
using RetType = std :: invoke_result_t < std :: decay_t < F > , std :: decay_t < Args > ... > ;
if ( stop_ . load ()) {
throw std :: runtime_error ( "ThreadPool is stopped" );
}
auto task = std :: make_shared < std :: packaged_task < RetType () >> (
std :: bind ( std :: forward < F > ( f ), std :: forward < Args > ( args )...));
std :: future < RetType > ret = task -> get_future ();
{
std :: lock_guard < std :: mutex > lc { mutex_ };
tasks_ . emplace ([ task ] {( * task )(); });
}
cv_ . notify_one ();
return ret ;
}
void start () {
for ( std :: size_t i = 0 ; i < num_threads_ ; ++ i ) {
pool_ . emplace_back ([ this ] {
while ( ! stop_ ) {
Task task ;
{
std :: unique_lock < std :: mutex > lc { mutex_ };
cv_ . wait ( lc , [ this ] { return stop_ || ! tasks_ . empty (); });
if ( tasks_ . empty ())
return ;
task = std :: move ( tasks_ . front ());
tasks_ . pop ();
}
task ();
}
});
}
}
};
测试 demo:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
int main () {
ThreadPool pool { 4 }; // 创建一个有 4 个线程的线程池
std :: vector < std :: future < int >> futures ; // future 集合,获取返回值
for ( int i = 0 ; i < 10 ; ++ i ) {
futures . emplace_back ( pool . submit ( print_task , i ));
}
for ( int i = 0 ; i < 10 ; ++ i ) {
futures . emplace_back ( pool . submit ( print_task2 , i ));
}
int sum = 0 ;
for ( auto & future : futures ) {
sum += future . get (); // get() 成员函数 阻塞到任务执行完毕,获取返回值
}
std :: cout << "sum: " << sum << '\n' ;
} // 析构自动 stop()
可能的运行结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
Task 0 is running on thr : 6900
Task 1 is running on thr : 36304
Task 5 is running on thr : 36304
Task 3 is running on thr : 6900
Task 7 is running on thr : 6900
Task 2 is running on thr : 29376
Task 6 is running on thr : 36304
Task 4 is running on thr : 31416
🐢🐢🐢 1 🐉🐉🐉
Task 9 is running on thr : 29376
🐢🐢🐢 0 🐉🐉🐉
Task 8 is running on thr : 6900
🐢🐢🐢 2 🐉🐉🐉
🐢🐢🐢 6 🐉🐉🐉
🐢🐢🐢 4 🐉🐉🐉
🐢🐢🐢 5 🐉🐉🐉
🐢🐢🐢 3 🐉🐉🐉
🐢🐢🐢 7 🐉🐉🐉
🐢🐢🐢 8 🐉🐉🐉
🐢🐢🐢 9 🐉🐉🐉
sum : 90
它支持任意可调用类型,当然也包括非静态成员函数。我们使用了 std::decay_t,所以参数的传递其实是按值复制,而不是引用传递,这一点和大部分库的设计一致。示例如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
struct X {
void f ( const int & n ) const {
std :: osyncstream { std :: cout } << & n << '\n' ;
}
};
int main () {
ThreadPool pool { 4 }; // 创建一个有 4 个线程的线程池
X x ;
int n = 6 ;
std :: cout << & n << '\n' ;
auto t = pool . submit ( & X :: f , & x , n ); // 默认复制,地址不同
auto t2 = pool . submit ( & X :: f , & x , std :: ref ( n ));
t . wait ();
t2 . wait ();
} // 析构自动 stop()
我们的线程池的 submit 成员函数在传递参数的行为上,与先前介绍的 std::thread 和 std::async 等设施基本一致。
构造函数和析构函数:
构造函数:初始化线程池并启动线程 。 析构函数:停止线程池并等待所有线程结束。 外部接口:
stop():停止线程池,通知所有线程退出(不会等待所有任务执行完毕)。submit():将任务提交到任务队列,并返回一个 std::future 对象用于获取任务结果以及确保任务执行完毕。start():启动线程池,创建并启动指定数量的线程。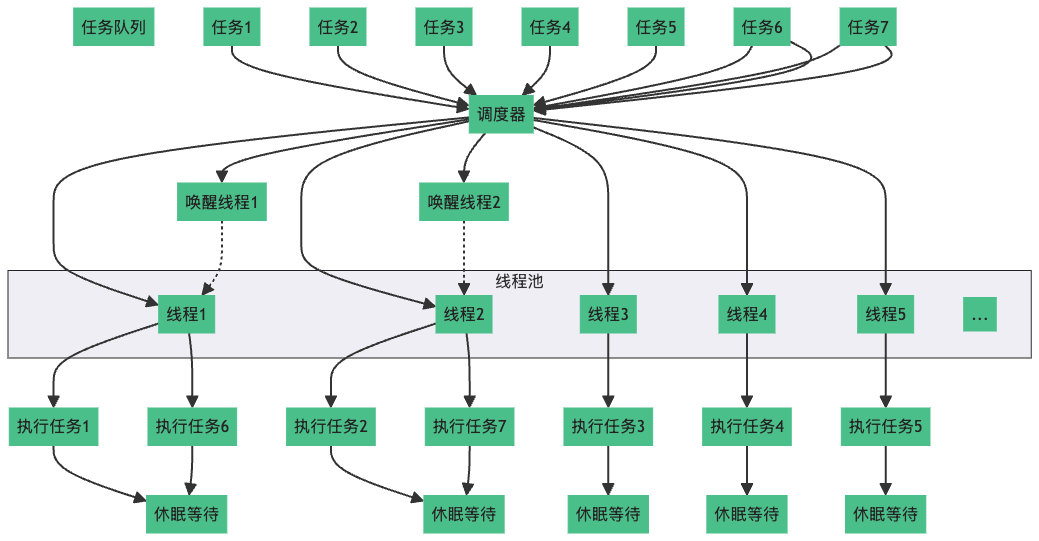
 支付宝
支付宝 微信
微信