分布式推理优化技术
分布式通信原语
在大模型分布式训练或推理时,常用到一些分布式通信原语,这里做一个简单总结
Broadcast(一对多)
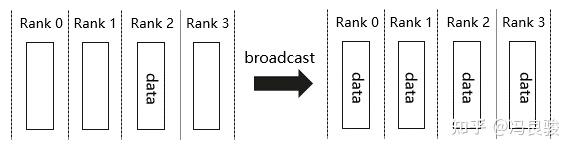
在集合通信中,如果某个节点想把自身的数据发送到集群中的其他节点,那么就可以使用广播 Broadcast 的操作。Broadcast 代表广播行为,执行 Broadcast 时,数据从主节点 2 广播至其他各个指定的节点(0~3)。 Broadcast 操作是将某节点的输入广播到其他节点上,分布式机器学习中常用于网络参数的初始化。
如图中,从单个 sender 数据发送到其他节点上,将 2 卡大小为 1xN 的 Tensor 进行广播, 最终每张卡输出均为[1xN]的矩阵。操作过后,所有的进程上数据一致。
应用场景
Broadcast 将一张 GPU 卡上的数据同步到其他所有的 GPU 卡上,其应用场景有: 数据并行的初始化:1)确保每张卡上的初始参数是一致的;2)确保每张卡上模型相同。
Scatter(一对多)
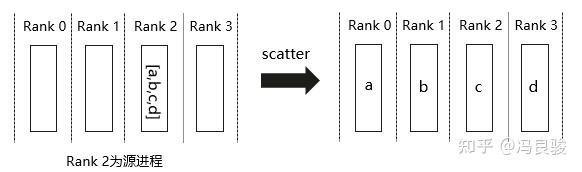
Scatter 操作表示一种散播行为,将主节点的数据进行划分并散布至其他指定的节点。Scatter 与 Broadcast 非常相似,都是一对多的通信方式,不同的是 Broadcast 的2号进程将相同的信息发送给所有的进程,而 Scatter 则是将数据的不同部分,按需发送给所有的进程。在分布式场景下,一般是将源进程上数据列表中的N个值按顺序分散到通讯组中的N个进程中。
应用场景
模型并行里初始化时将模型 scatter 到不同的 GPU 上;数据并行,将数据按卡数分发到不同的 GPU 上。
Gather(多对一)
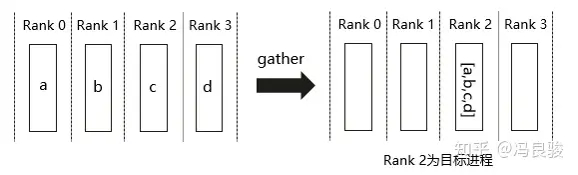
Gather 操作将多个 sender 上的数据收集到单个节点上,Gather 可以理解为反向的 Scatter。 Gather 操作会从多个进程里面收集数据到一个进程上面。
Reduce(多对一)
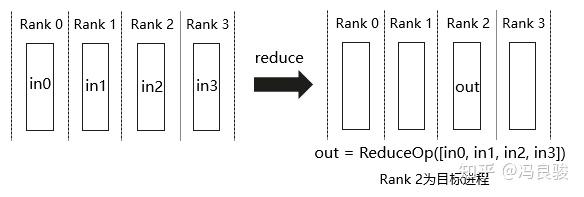
Reuduce 称为规约运算,是一系列简单运算操作的统称,细分可以包括:SUM、MIN、 MAX、PROD、LOR 等类型的规约操作。Reduce 从多个 sender 那里接收数据,最终 combine 到一个节点上。相比与all_reduce操作,不同点在于reduce在执行时需要指定目标进程,只有目标进程会收到最终的归约向量。
应用场景
如数据并行时的梯度规约
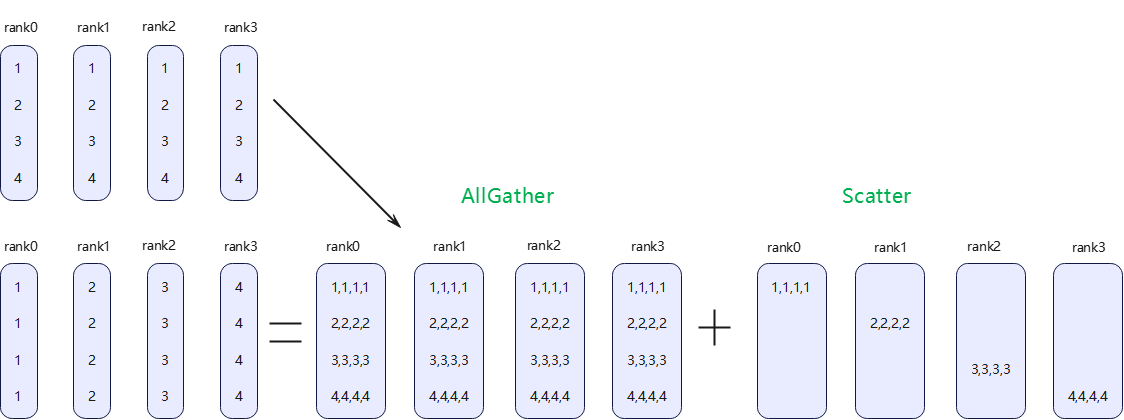
All Gather(多对多)
All Gather 会收集所有进程上的数据,并同步给所有进程。从最基础的角度来看,All Gather 相当于一个 Gather 操作之后跟着一个 Broadcast 操作。
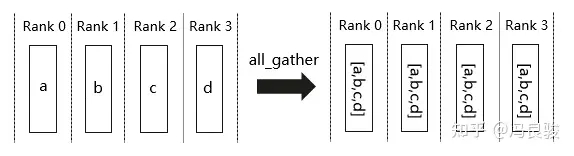
AllReduce(多对多)
Reduce 是一系列简单运算操作的统称,All Reduce 则是在所有的进程上都应用同样的 Reduce 操作。All Reduce 操作可通过单节点上 Reduce + Broadcast 操作完成。在 NCCL 中的 All Reduce 中,则是从多个 sender 那里接收数据,最终合并和分发到每一个节点上。
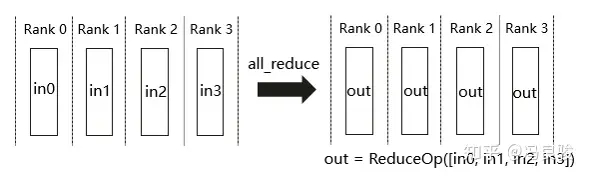
ReduceScatter(多对多)
归约分散操作,该操作行为上可以理解为在一个通信组内依次执行一个reduce操作和一个scatter操作,其示意图如下:
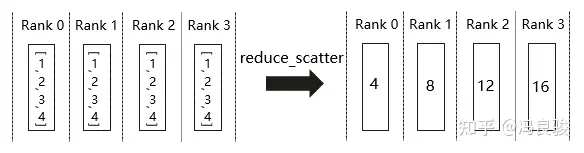
首先,执行一个reduce操作(比如在0卡上),将每张卡上的1、2、3、4收集,那么0卡上得到4、8、12、16。然后执行一个scatter操作,将数据分割到不同卡上,每张卡的数据依次为:4、8、12、16。
在大模型训练过程中,常常会执行all_reduce操作,确保每张卡的parameter相同,为了是实现并行化,一般会将all_reduce操作进行拆分,一般由一个reduce_scatter和一个all_gather组成。如下所示:
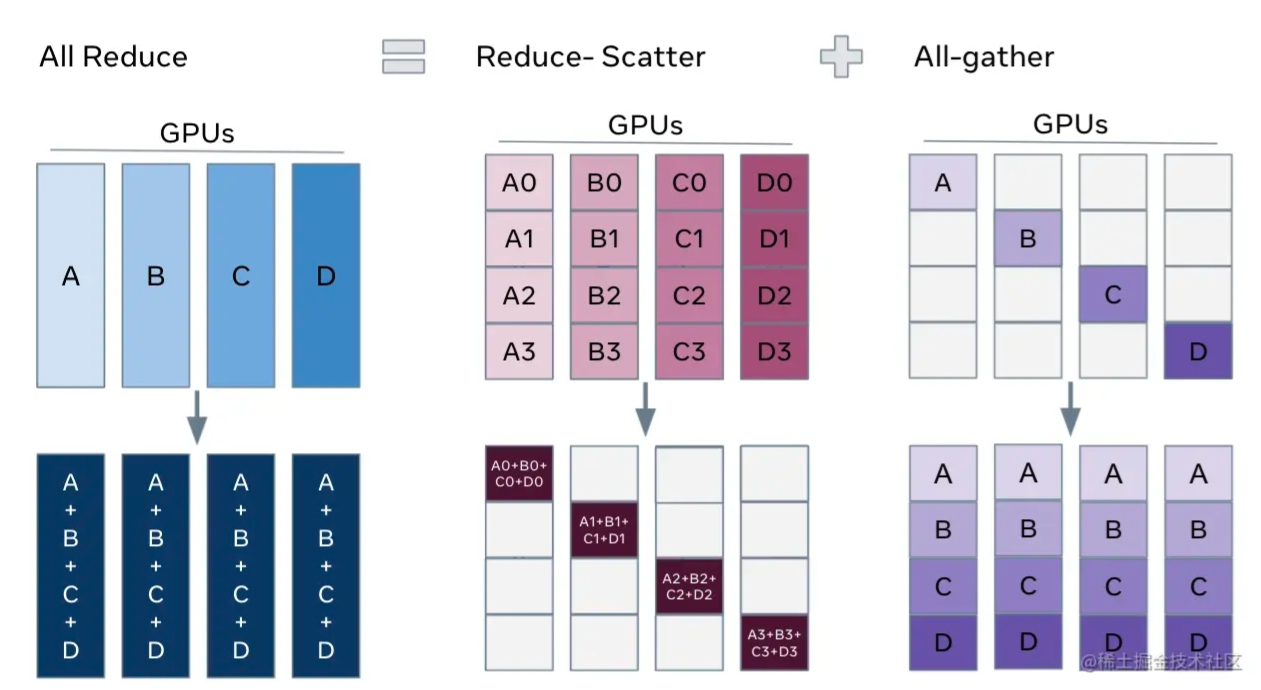
AllToAll(多对多)
All to All 作为全交换操作,每个进程的接收缓冲区和发送缓冲区都是一个分为若干个数据块的数组。All to All 的具体操作是:将进程 i 的发送缓冲区中的第 j 块数据发送给进程 j,进程 j 将接收到的来 自进程 i 的数据块放在自身接收缓冲区的第 i 块位置。
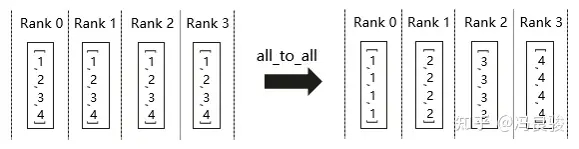
All to All 与 All Gather 区别:All Gather 操作中,不同进程向某一进程收集到的数据是完全 相同的,而在 All to All 中,不同的进程向某一进程收集到的数据是不同的。在每个进程的发送 缓冲区中,为每个进程都单独准备了一块数据。
全体到全体操作,该操作需要一个通信组中的N个进程各自提供一个含有N个元素的列表,对N个元素分别执行一次all_gather和scatter操作,如下所示:
一些常见问题
为什么不缓存Q,而要缓存KV?
因为分析attention计算可以知道,预测下一个token只用到了当前的query信息,而没有用到之前的query信息,所以不用缓存Q; 在序列的t位置,Q只有当前位置的,参与了计算,而K和V多个位置参与了计算,所以需要KV Cache,而不需要Q Cache。
为什么 DeepSeek 使用 FP8 而 Qwen 使用 BF16
为什么 CPU 需要三层 Cache 而 GPU 只需要两层;
CPU三级缓存介绍:https://blog.csdn.net/weixin_43719763/article/details/128602160
CPU三级缓存主要为了用于不同级别的数据访问,L1/L2是私有的,而L3是共享的,这样可以减少核心之间的数据竞争,降低数据访问延迟。而GPU由于线程数量较多,每个线程对缓存的压力较小,无需为单个线程进行优化缓存层级。而且GPU数据重用集中在相邻线程(如卷积核滑动窗口),L1/L2 缓存+共享内存即可满足。
分布式并行方法
数据并行(DP)、张量并行(TP)、流水线并行(PP)、上下文并行(CP)、专家并行(EP)以及序列并行(SP)。
为什么分布式并行很重要?
一个70B参数的FP16模型,仅模型权重就需要约140GB的存储空间,远超任何单张主流GPU的显存容量。此外,训练过程中产生的优化器状态、梯度和中间激活值,更是将内存需求推向了TB级别
训练如此大规模的模型需要巨大的计算资源,单一设备的计算能力根本无法满足需求。通过分布式并行,可以将计算任务分解到多个设备上,实现高效的并行计算。
基础并行策略(DP、TP、PP)
DP (Data Parallelism, DP)
核心原理:数据并行是最直观、最常用的并行方式。其核心思想是“模型复制,数据分片”。即将完整的模型副本放置在每一个计算设备(如GPU)上,然后将一个大的训练批次(mini-batch)分割成多个更小的微批次(micro-batch),每个设备独立处理一个微批次的数据。
工作流程:
- 分发: 将一个全局批次的数据切分,分发给各个GPU。
- 前向传播: 每个GPU使用其上的模型副本独立计算其微批次数据的前向传播,得到损失。
- 反向传播: 每个GPU独立计算梯度。梯度同步: 这是DP的关键步骤。所有GPU上的梯度需要通过一个集合通信操作(通常是All-Reduce)进行聚合(如求和或求平均),以确保每个GPU最终都得到全局梯度 。
- 权重更新: 每个GPU使用同步后的全局梯度独立更新其本地的模型副本,从而保证所有副本在下一步开始前保持一致。
这里涉及到本文的第一个“分布式通信”原语,全归约(All-Reduce),它处理 GPU 实例和节点之间的同步和通信。其实很好理解:就是每一个GPU把数据发送给其余GPU,每一个GPU对于接收到的数据进行求和。 Reduce(归约):将多个GPU的数据发送到指定的GPU然后求和。
DP方法的优缺点:
优点:
- 实现简单,易于集成到现有训练框架中
- 适用于大多数标准模型架构
- 扩展性较好,可轻松扩展到多GPU集群
缺点:
- 内存瓶颈显著,无法解决"模型太大,单卡放不下"的问题
- 随着GPU数量增加,All-Reduce操作的通信开销成为主要瓶颈
- 扩展效率受限于通信带宽和延迟
关键优化:ZeRO (Zero Redundancy Optimizer)
为了克服DP的内存冗余问题,ZeRO[1]技术应运而生。它通过在不同设备间分割和管理模型状态(而不仅仅是数据)来极大地优化内存使用。

ZeRO-DP使得数据并行也能用于训练单卡无法容纳的大模型,是当前大规模训练框架(如DeepSpeed[2])的核心技术之一。
TP (Tensor Parallelism, TP)
在使用 ZeRO 对模型的参数、梯度和优化器状态进行了分片,但当激活内存超过内存预算时,遇到了瓶颈。张量并行(TP),这是一种分片权重、梯度和优化器状态以及激活的方法——而且无需在计算之前将它们全部收集起来。
张量并行利用了矩阵乘法的数学特性,A×B 。
$$ \begin{aligned} A\cdot B &= A\cdot [B_{1}, B_{2} \cdots] = [AB_{1}, AB_{2} \cdots] \\\\ A\cdot B &= [A_{1}, A_{2} \cdots] \begin{bmatrix} B_{1} \\ B_{2} \\ \vdots \end{bmatrix} = \sum_{i=1}^{n}A_{i}B_{i} \end{aligned} $$这意味着可以通过单独计算 B 的每一列或单独计算每一行并将结果组合起来来进行矩阵乘法。示例如下:
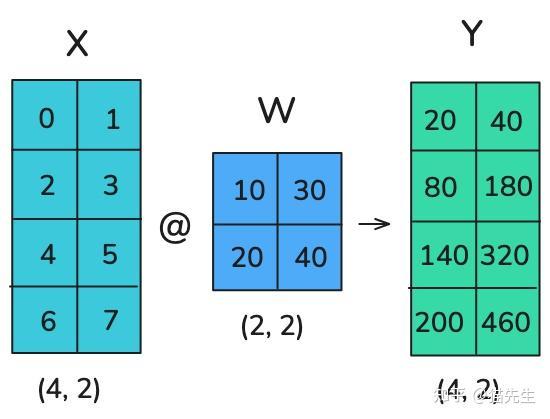
在张量并行中,张量会沿着特定维度被分割成 N 个片段,并分布到 N 个 GPU 上。矩阵可以在列或行上进行分割,从而实现行或列并行。
第一个选项是使用按列(也称为按列线性)分片:将完整输入矩阵复制到每个工作节点,需要一种称为广播(broadcast)的操作,并将权重矩阵按列拆分。然后输入与部分权重矩阵相乘,最后使用全聚合(all-gather)操作合并结果。
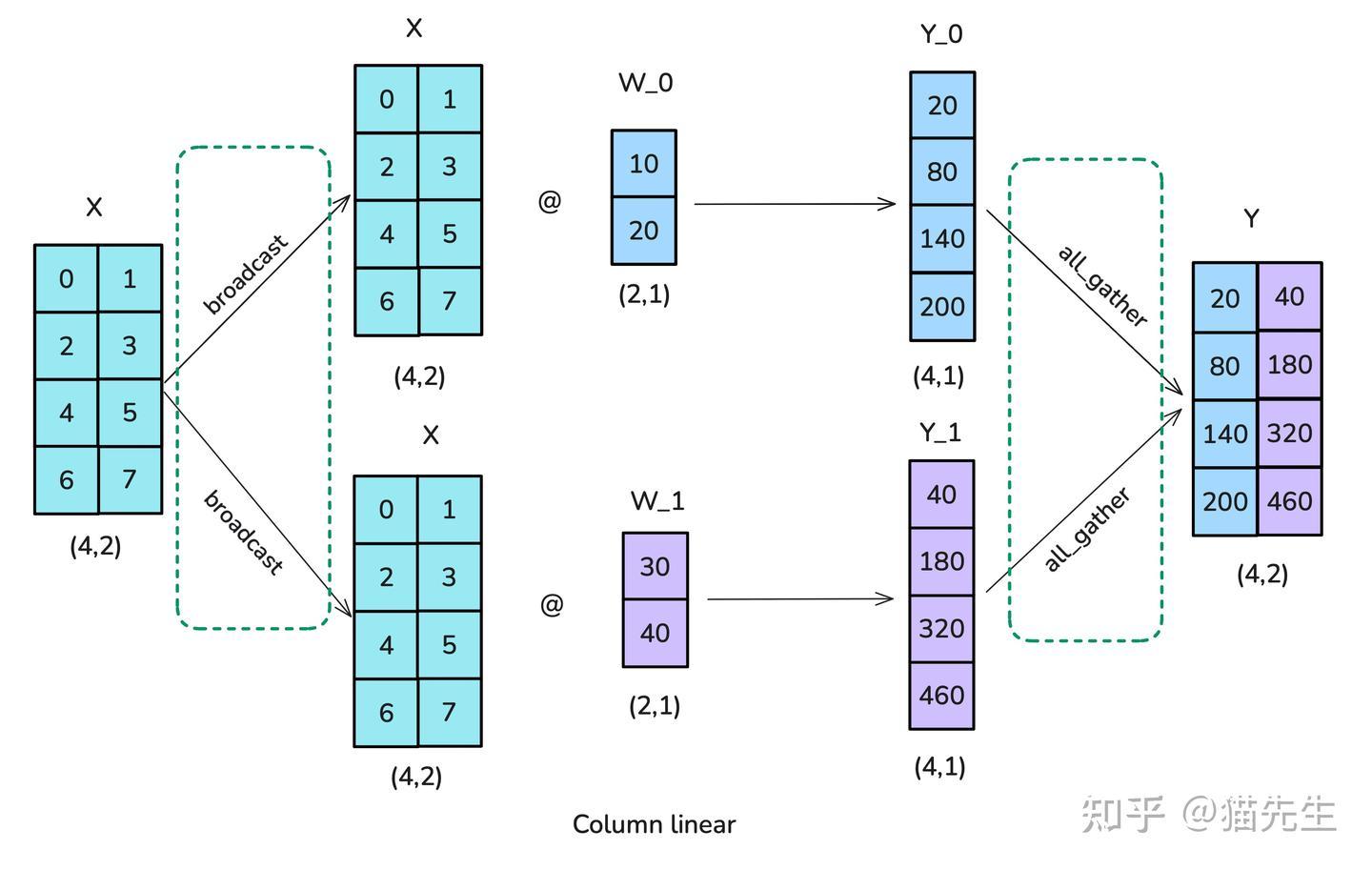
“分布式通信”原语: 广播(broadcast):将一个GPU上的数据同时发送到所有其他GPU。 全聚合(all-gather):每一个GPU把数据发送到其余所有GPU,每个GPU对于接受到的数据拼接为完整数据。
第二种选项称为按行(或行线性)分片:行线性意味着将权重矩阵按行分割成块。因此,需要使用散播(scatter)操作(第四种分布式通信原语!)而不是列线性分片中所使用的广播操作。每个工作节点上的结果已经处于正确的形状,但需要求和以得到最终结果,因此这种场景也需要一个全归约操作:
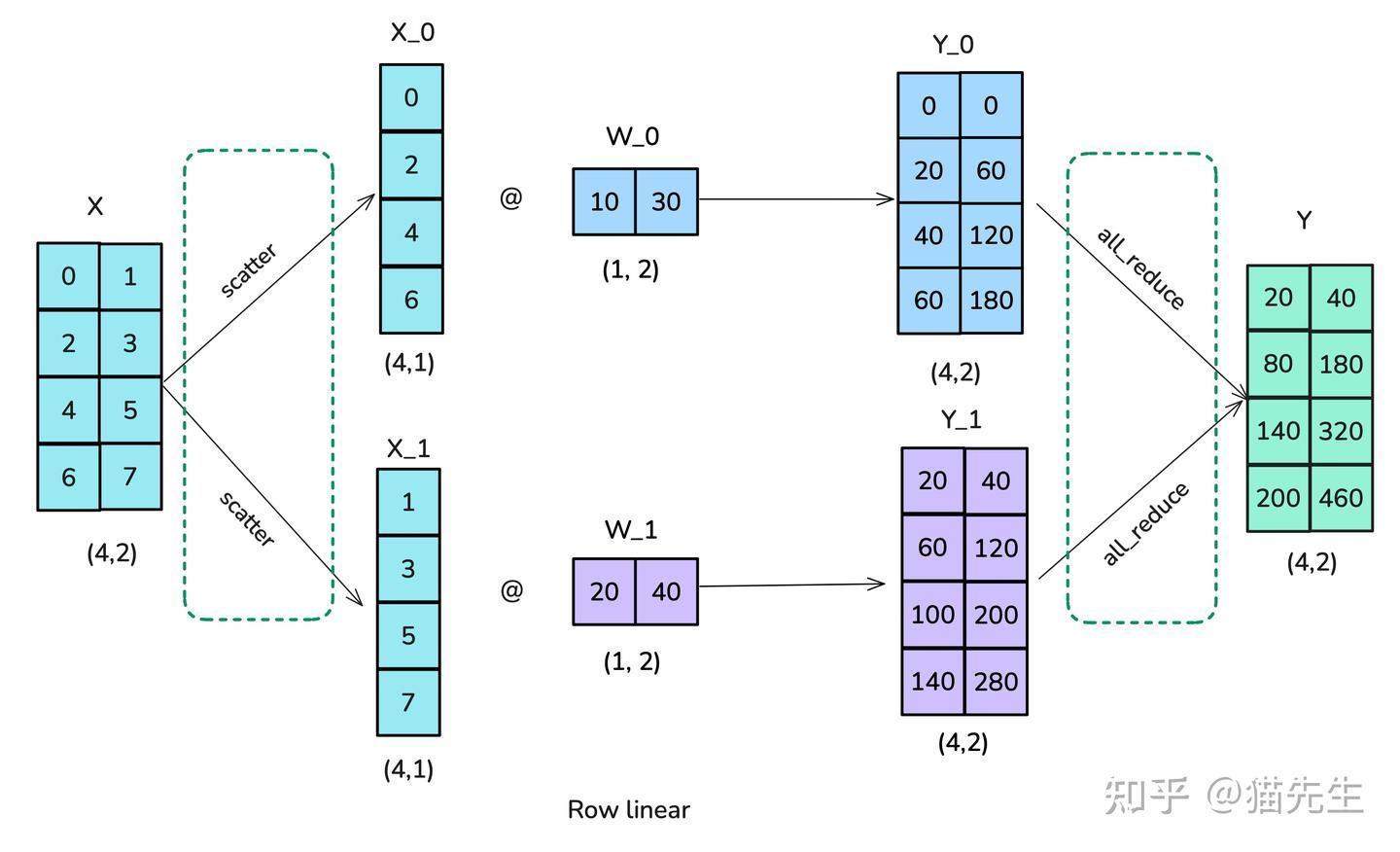
“分布式通信”原语: 散播(scatter):把一个GPU上的数据切分为多块,按照顺序向其他GPU发送数据块。
核心原理: 张量并行,又称模型内部并行(Intra-layer Model Parallelism),旨在解决单层网络计算量过大或参数过多无法在单个设备上处理的问题。它将模型中的单个张量(如权重矩阵)沿特定维度切分到多个GPU上,并在这些GPU上协同完成运算。
工作流程(以Transformer中的MLP层为例):
一个标准的MLP层包含两次线性变换。假设我们将模型并行到N个GPU上:
- 第一个线性层的权重矩阵A可以按列切分成 [A1, A2, …, AN]。输入X与每个Ai相乘得到Xi * Ai。这是一个并行的矩阵乘法,无需通信。
- 第二个线性层的权重矩阵B可以按行切分成 [B1; B2; …, BN]。在进行第二次矩阵乘法前,需要将第一步的输出结果 [Y1, Y2, …, YN] 通过All-Gather操作在所有GPU间聚合,得到完整的Y。然后每个GPU计算Y * Bi。
- 最后,将各个GPU上的结果通过Reduce-Scatter或简单的加和操作得到最终输出。
Megatron-LM[3]框架是张量并行的杰出代表,它巧妙地设计了Transformer中注意力层和MLP层的并行计算方式,将通信操作与计算有效结合。
优缺点分析
| 优点 | 缺点 |
|---|---|
| (1)直接减少了单个GPU上的内存占用(包括模型参数和激活值)(2)使得训练远超单卡内存限制的模型成为可能(3)计算粒度细,可以更好地利用GPU的并行计算能力 | (1)通信开销巨大且频繁,通常仅限于在单个计算节点内部进行高效扩展(2)对设备间的通信带宽要求极高(3)实现复杂度较高,需要仔细设计通信模式 |
流水线并行 (Pipeline Parallelism, PP)
核心原理:流水线并行,又称层间模型并行(Inter-layer Model Parallelism),将模型的不同层(或层块)分配到不同的GPU上,形成一个计算"流水线"。数据在一个设备上完成部分层的计算后,其输出(即激活值)被传递到下一个设备,继续后续层的计算。
工作流程:
- 朴素流水线: 最简单的方式是将一个批次的数据依次通过所有GPU。但这会导致严重的“流水线气泡”(pipeline bubble),即在任何时刻,只有一个GPU在工作,其他GPU都在等待,利用率极低。
- 微批次流水线 (Micro-batching): 为了解决气泡问题,GPipe[4]等框架引入了微批次的概念 。它将一个大的批次(mini-batch)再切分成多个微批次(micro-batches),并将这些微批次依次送入流水线。这样,当第一个微批次在第二个GPU上计算时,第二个微批次就可以在第一个GPU上开始计算,实现了计算的重叠,从而显著减少了GPU的空闲时间。
优缺点分析
| 优点 | 缺点 |
|---|---|
| (1)同样能有效降低单个GPU的内存占用(2)通信开销相对较低,因为通信只发生在流水线中相邻的两个阶段之间(3)通信内容主要是激活值,而非整个模型参数(4)实现相对简单,易于调试 | (1)仍然存在无法完全消除的"气泡"问题,特别是在流水线的启动和排空阶段(2)要求对模型进行合理的切分,以实现各阶段的负载均衡(3)“木桶效应"会限制整体性能,最慢的阶段决定整体吞吐量(4)流水线深度增加会导致额外的启动和结束延迟 |
长序列并行策略:序列、上下文并行
随着模型对长文本处理能力的需求日益增长,输入序列长度成为新的内存瓶颈。传统的TP和PP主要解决参数存储问题,而SP和CP则专注于解决因序列过长导致的激活值内存爆炸问题。
序列并行 (Sequence Parallelism, SP)
核心原理: Transformer架构中的自注意力机制(Self-Attention)需要在序列维度上进行全局计算,这使得沿序列维度进行并行化变得困难。序列并行巧妙地绕过了这一点,它选择性地对那些在序列维度上计算独立的模块(如LayerNorm、Dropout和MLP中的逐点操作)的输入激活进行切分。[5]
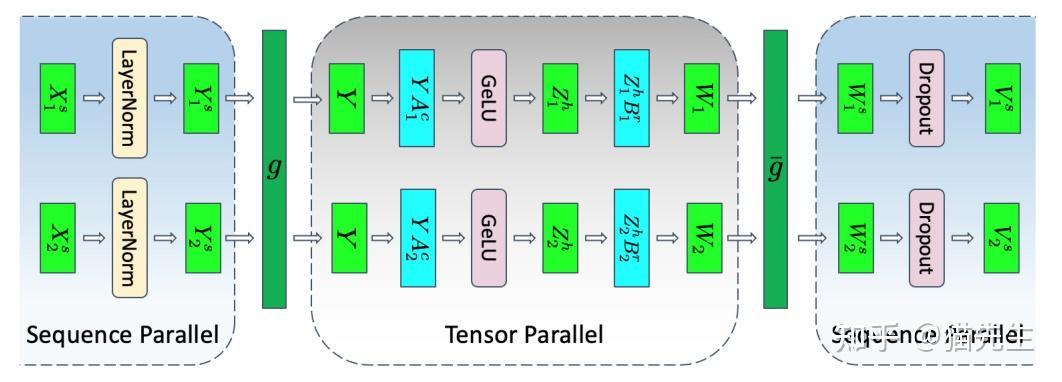
工作流程:
在进入非并行化的模块(如自注意力)之前,被切分的激活需要通过All-Gather操作在序列维度上拼接回完整的张量。 在完成该模块的计算后,输出的激活可以再次被切分,或者通过Reduce-Scatter操作将计算(如梯度累加)分散到各个设备上。
价值与定位
SP是TP的一个重要补充。TP虽然切分了权重,但每个GPU上仍然需要存储完整的激活张量,这在长序列场景下会成为内存瓶颈。SP通过切分激活,进一步降低了内存占用,使得在有限的显存下能够训练更长的序列或使用更大的批次大小。截至2024年的研究表明:将SP与PP结合(如Mnemosyne 2D并行化[6])可以在长上下文预填充处理中达到80%以上的扩展效率。
应用场景
- 长文本处理:对于需要长文档、代码或对话的历史记录等场景,SP可以显著降低内存占用,支持更长的上下文窗口
- 批量处理:在需要同时处理多个独立任务时,SP可以提高GPU利用率,减少空闲时间
“分布式通信”原语: 散播归约(Reduce-Scatter):先做Scatter再做Reduce,先将GPU的数据分割为多个数据块,然后每一块数据按GPU序列进行散播Scatter。对所有的GPU都进行散射之后,当前GPU所接受到的所有数据块进行求和,也就是Reduce归约。
上下文并行 (Context Parallelism, CP)
核心原理: 上下文并行[7]是处理超长序列的一种更激进的策略。与SP只切分部分激活不同,CP将网络输入和所有中间激活都沿序列维度进行划分。
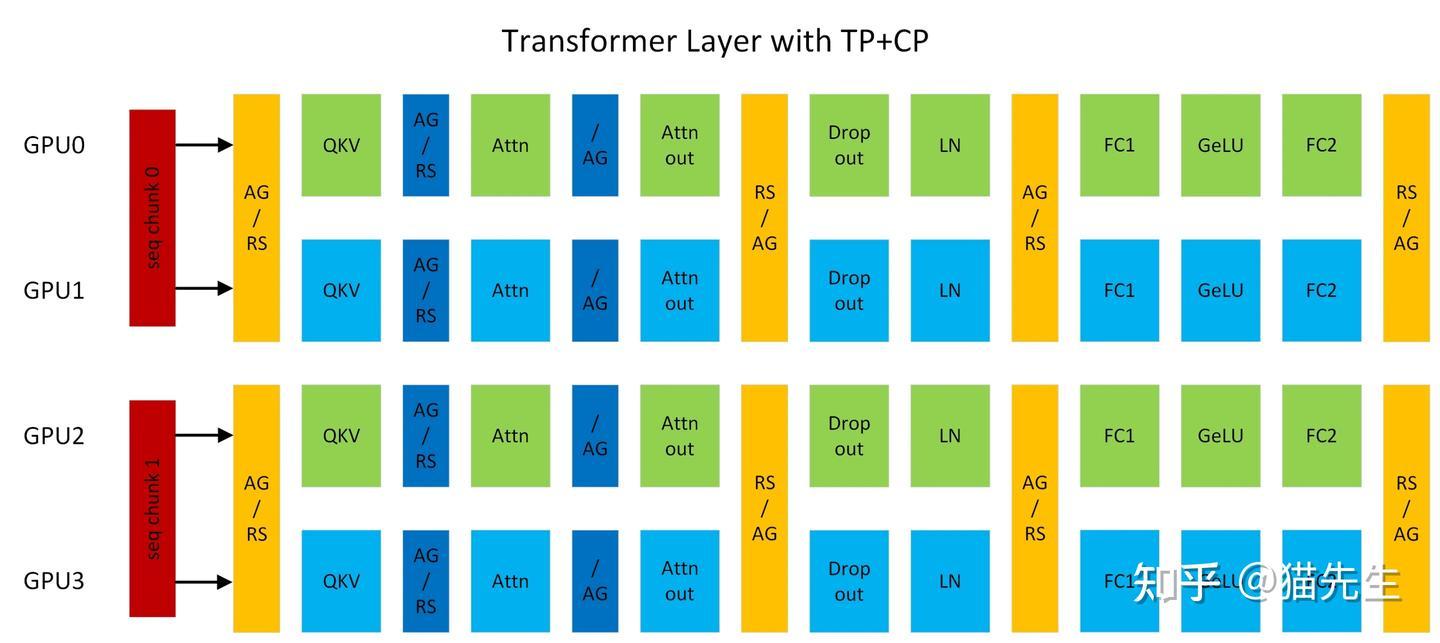
工作流程(以注意力机制为例):
CP的实现方式如下:
- 输入切分: 将长度为S的输入序列切分为N份,每个GPU处理长度为S/N的子序列。
- 本地Q, K, V计算: 每个GPU根据自己的子序列计算出局部的Q, K, V张量。
- 全局K, V同步: 在进行注意力计算之前,所有GPU需要通过一次All-Gather通信,将其本地的K和V张量广播给所有其他GPU。这样,每个GPU就拥有了完整的K和V张量,但只拥有局部的Q张量。
- 注意力计算: 每个GPU使用其局部的Q和全局的K, V来计算注意力得分和输出,这部分计算是并行的。
- 反向传播: 梯度计算也遵循类似的通信模式,通常涉及Reduce-Scatter操作。
价值与定位:
CP的主要目标是最大程度地减少激活值内存占用,从而支持数万甚至数十万长度的上下文窗口。Amazon SageMaker 和 Megatron Core 等框架已经集成了CP功能 。其代价是在注意力层内部引入了额外的通信开销,但对于那些因激活内存而无法运行的超长序列场景,CP是必不可少的解决方案。
| 优点 | 缺点 |
|---|---|
| (1)极大降低内存占用(2)适用于需要处理数十万tokens的场景(3)可以与其他并行策略结合使用 | (1)引入额外的通信开销,尤其在注意力层(2)实现复杂度高,需要特殊硬件支持(3)可能影响计算效率,增加延迟 |
专家并行 (Expert Parallelism, EP)
核心原理: MoE架构用一组稀疏激活的“专家”网络(通常是FFN层)替换了传统Transformer中的密集FFN层。对于每个输入的token,一个可学习的“门控网络”(Gating Network)或“路由器”(Router)会动态地选择一小部分(如Top-2)专家来处理它 。这样,模型的总参数量可以非常巨大(所有专家参数之和),但每个token的实际计算量(FLOPs)却保持不变或仅少量增加。
专家并行 (EP) 实现:
EP是为MoE模型量身定制的并行策略。其核心思想是将不同的专家分配到不同的GPU上。
- 专家分发: 将E个专家平均分配到N个GPU上,每个GPU拥有E/N个专家。
- 路由计算: 所有GPU上的token首先通过门控网络,计算出各自应该被发送到哪些专家。
- 全局通信 (All-to-All): 这是EP中最关键也最昂贵的步骤。所有GPU参与一次All-to-All通信,将每个token发送到其目标专家所在的GPU。
- 专家计算: 每个GPU用其本地的专家处理接收到的token。
- 结果返回 (第二次All-to-All): 计算完成后,再次通过All-to-All通信将处理结果发送回token原始的GPU。
优缺点分析
| 优点 | 缺点 |
|---|---|
| (1)实现计算成本与模型参数量的解耦(2)是目前扩展模型至万亿参数规模的最有效路径(3)支持模型参数量与计算量分离扩展(4)可以通过增加专家数量而非计算量来扩展模型 | (1)高通信开销:两次All-to-All通信对网络带宽要求极高(2)负载不均:路由策略可能导致某些专家过载而另一些空闲(3)训练不稳定:路由器的学习过程可能很脆弱,导致训练崩溃(4)实现复杂度高,需要特殊硬件和软件支持 |
综合策略与性能基准
在实践中,训练一个顶尖的大模型(如70B以上)绝不会只使用一种并行策略,而是将多种策略组合起来,形成所谓的3D或4D并行。
常见组合范式:
一个典型的4D并行配置可能是:
- 张量并行 (TP): 在单台服务器内部的GPU之间使用,以利用高速的NVLink互联。
- 流水线并行 (PP): 在多台服务器之间使用,以切分模型的深度。
- 数据并行 (DP): 在整个集群的所有设备上应用,以扩大总批次大小,加速收敛。
- 专家/序列/上下文并行 (EP/SP/CP): 根据模型架构(是否为MoE)和应用场景(是否为长上下文)选择性地加入,作为第四个维度。
 支付宝
支付宝 微信
微信