GPU及CUDA基本概念
GPU 架构
SM(Streaming Multiprocessor)结构

其中包含一些核心组件:
- CUDA core(即Streaming Processor,SP):其中包含整数处理单元和单精度浮点数处理单元,用于执行基本的数值运算。不同架构中CUDA core数量不同,这个数量在一定程度上体现了GPU的计算能力(并不是完全决定,还有如时钟频率,内存带宽,指令集等其他影响因素)
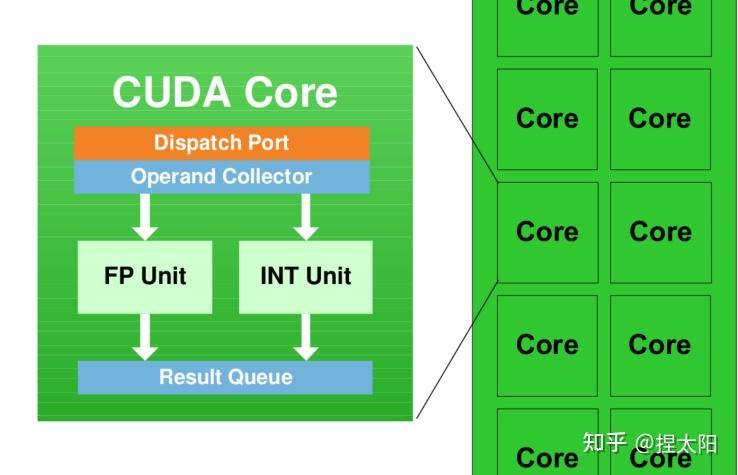
Register File:寄存器文件。存放指令操作数;也有一些特殊寄存器用于存放系统变量,例如grid维度,thread blcok维度,线程id等等。
Loca/Store Units(LD/ST):执行内存(显存、shared memory)读写数据命令。
Special Function Units(SFU):执行一些特殊函数,如sqrt,sin,cos等。
Warp Scheduler:GPU线程调度执行时是以一组线程(warp)为单位的,Warp Scheduler从驻留在SM上的warp中选 择合适的warp用于执行。
Dispatch Unit:负责从Warp Scheduler选中的线程中取出要执行的指令发射到CUDA core去执行。
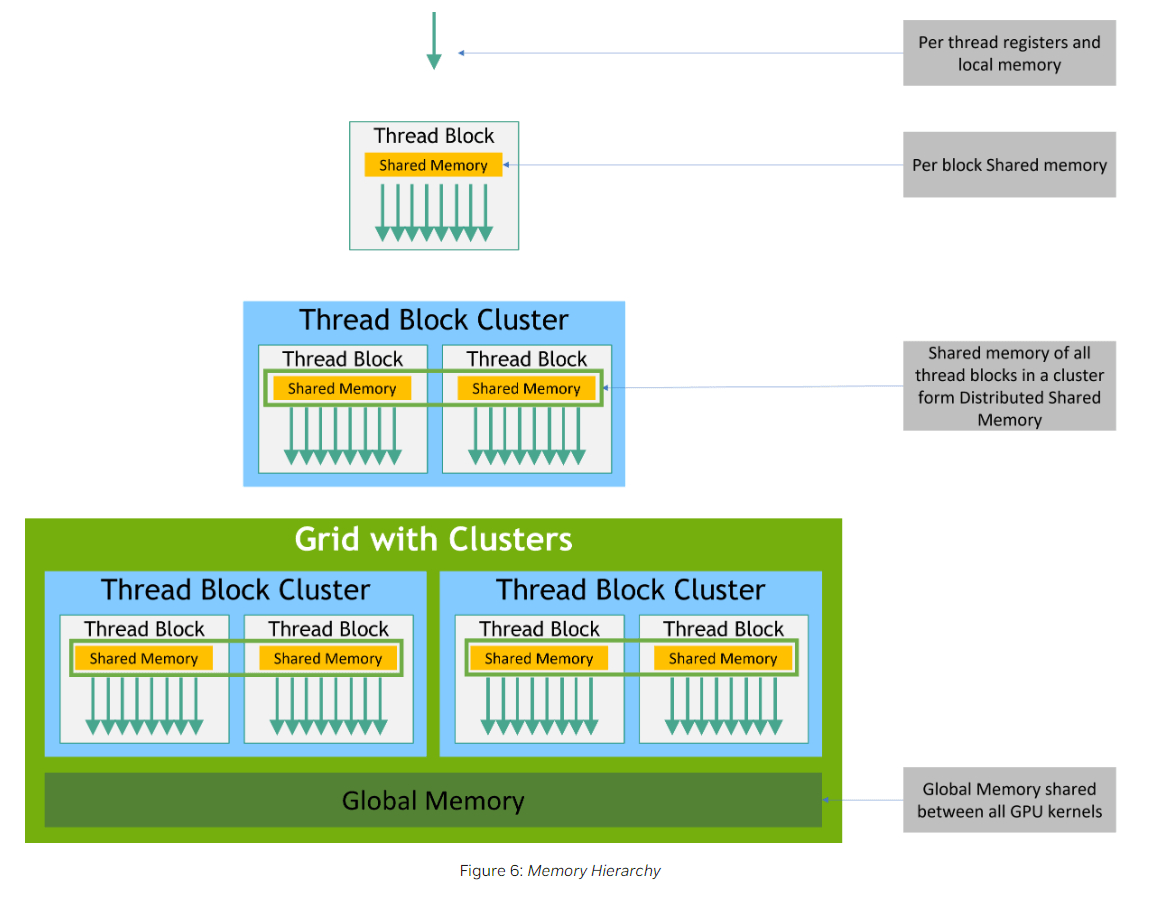
Shared Memory/L1 Cache:shared memory可以用于同一个thread block中的线程间互相通信,是可以通过编程读写的。L1 Cache则不能被编程,由GPU决定存放和淘汰内容。这里把Shared Memory和L1 Cache放在一起是因为它们在物理存储上是共用的,可以通过API控制两者的配比。
L2 Cache:SM 到全局内存中间的缓存,latency 会比访问全局内存小,缓存全局内存以及local memory所有SM共享一个L2 Cache
常量、纹理缓存与全局内存缓存:有的gpu架构这三类内存结构也同样存在于一个SM中:
Hopper架构
由于实习期间使用的都是 H20 集群,因此学习一下 Hopper 架构的特点
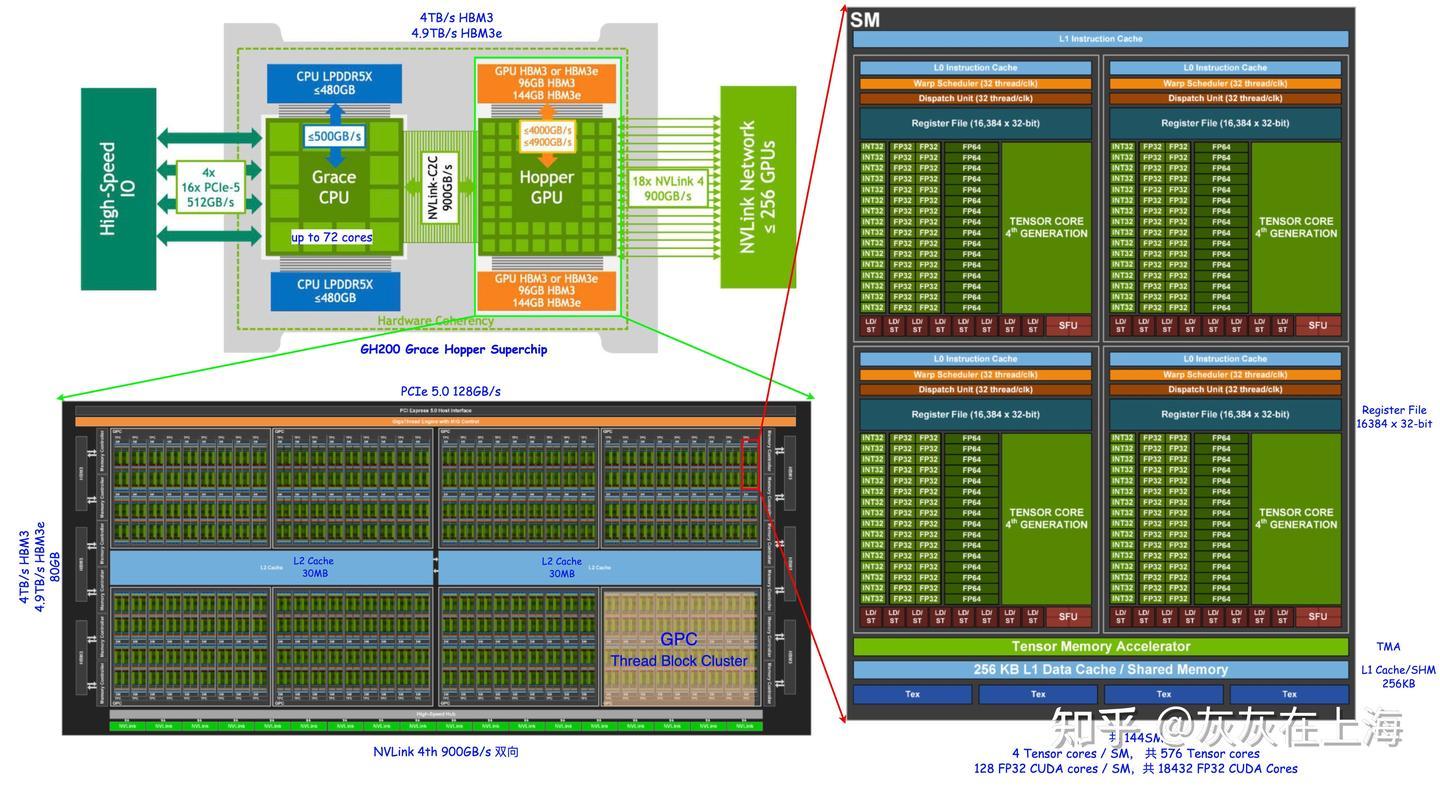
- 新增了 Block Cluster 这一线程层次,提供跨 Block 的 shared memory 的访问。Hopper 架构在 Cluster 内部,位于 L1 和 L2 Cache 之间新增了一层SM-to-SM Network。Thread Block Cluster 内部的 SM 可以通过该层网络访问其他 SM 的 Shared Memory
- 访存计算异步执行:Hopper 在硬件层提供了 TMA 单元,在软件层可以通过 cuda::memcpy_async 使用 TMA 单元实现异步的 Global Memory 和 Shared Memory 之间的拷贝。
GPU线程调度
一个CUDA kernel对应一个grid,一个grid分成若干个thread block,每个thread block中包含若干线程。那么从硬件角度看,GPU在调度Kernel时,粗粒度看分成两个阶段,即SM分配和线程调度执行。
SM分配
GPU会根据SM资源情况来进行block的分配,只有当SM上剩余资源足够满足一个block的总资源需求时,SM才有可能被分配给当前block。这里的资源主要指共享内存和寄存器,即SM上的Shared Memory及寄存器是不能超额分配的;但CUDA core,SFU等指令执行单元则是可以超额分配的。
例如Fermi架构中每个SM上CUDA core只有32个,但是一个SM最大可以支持1536个线程,因为虽然不能同时执行这1536个线程的指令,但是可以对CUDA core进行时分复用,执行不同线程时进行上下文切换即可,GPU上的线程上下文切换效率远高于CPU上的线程切换,因为线程的寄存器已经事先分配好,切换时并不需要像CPU上那样把寄存器状态在主机内存上进行换入换出操作。
当然一个SM上最多能够支持多少个线程还是有硬性限制的,具体限制数值取决于具体架构。一个thread block分配到一个SM上之后就会驻留下来直到执行完毕,同一个grid中的thread block可能分配到不同的SM上,反过来同一个SM也可能被分配给来自不同grid的多个thread block;一个thread blcok分配到一个SM上之后,则称为Active thread block,一个SM被分配thread block之后则称为Active SM。
线程调度执行
在调度执行时,GPU并不会针对单个线程去调度,而是把一个thread block进一步划分为若干个Warp(线程束)为单位进行调度,一个warp包含32个线程(目前所有架构上都是32),每个Warp Sheduler每个时钟周期(cycle)选择一个Warp将其指令通过Dispatch Unit发射到执行单元。也就是说一个thread block中的线程只是在逻辑上是同步执行,但是在硬件层面则不一定。可以从资源分配和调度的角度对此与主机上的调度做一个类比,thread block类似于主机上的进程,是资源分配单位,warp类似于主机上的线程,是调度执行单位。
Warp有如下几种状态:
- Active:一个Acitve的thread block中的Warp都是Active的,也即已经分配到SM的Warp都是Active Warp。
- Stalled:当前Cycle暂时不能执行下一条指令的Warp,有多种情况可能导致Warp处于Stalled状态,常见的有:
- thread block内的线程同步,部分先执行的Warp必须等待同一个block内的后执行的Warp到达同一个同步点。
- 线程需要的数据还没有传输完成,需要等待数据。
- 下一条指令依赖于上一条指令的输出,但是上一条指令还没有执行完成。
- Eligible:当前Cycle已经准备好可以执行下一条指令的Warp。Warp Scheduler在选择Warp时只会从Eligible Warp中进行选取。
- Selected:被Warp Scheduler选中准备执行其中线程下一条指令的Warp。
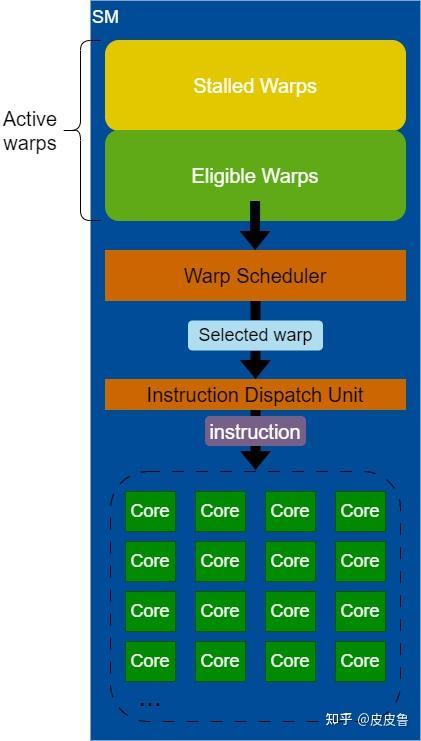
注意一个Warp中线程的同步性仅仅体现在调度上,即一个Warp中的所有线程是同时被Scheduler选中的,但是在指令发射和执行上则不一定了,至少可以从几个方面去看:
Instruction replay:同一条指令发射多次称为instruction replay。CUDA指令可以分为不同类型,不同类型指令使用不同类型的执行单元执行,例如memory的读写指令是通过LD/ST units执行,特殊函数如sin,cos是通过SFU执行,即并非所有指令都是通过CUDA core执行。而对于某种类型执行单元来说,一个SM上可能都没有32个,例如Fermi中一个SM上只有4个SFU,那么一个Warp执行cos指令时,就需要发射和执行8次。
Warp divergence:当一个Warp中的线程因为分支条件(如if else)不同而走到不同的路径时会造成warp divergence,此时不同分支的线程会形成不同分组,这些分组串行在不同的cycle执行
延迟隐藏
延迟隐藏就是指通过并行执行,充分利用硬件执行单元,使得不同操作能够在时间上重叠,最大化某一种或几种操作的吞吐量(延迟隐藏的主要优化目标是吞吐量,而不是单个操作的时长)。比如这里的当Warp等待内存时,SM立即切换其他就绪Warp。
了解详情可以进一步学习:利特尔法则(little’s law)
warp的划分
CUDA线程与数组在内存中的排布类似,也分为逻辑视图和硬件视图,在逻辑视图上,一个thread block可能是1到3维的,但是在硬件视图上,这些线程上仍然是1维排布的,即按row-major方式将连续的32个线程组成一个Warp,用公式表达就是:
| |
提示
当一个thread block中的线程总数不是32的整数倍时,从编程视角看,最后一个Warp是不满32个线程的,但是在GPU硬件上仍然会占用32个线程的资源,只是其中部分线程会被标识为不活跃线程,这种情况下就会造成一些资源的浪费,所以在实际使用时,要尽量保证thread block中的线程数为32的整数倍。
warp divergence
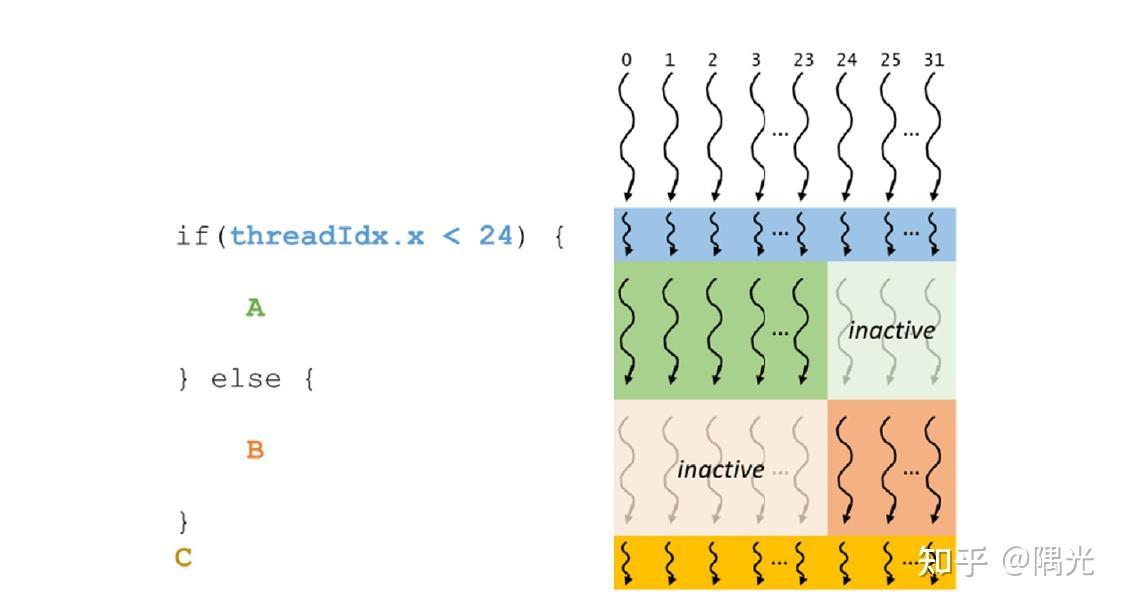
Warp Divergence是指同一个Warp中的不同线程由于分支条件(例如if else)不同而进入不同的代码分支的情况。这个在CPU上的多线程不是太大问题,但是在CUDA中则会导致性能下降,因为在发生Warp Divergence时,Warp中走不同分支的线程会串行化执行,以一个2路分支为例,如下伪代码:
| |
假设Warp内前一半线程condition 为true ,后一半线程condition为false,那么执行时两部分线程就分开串行执行了,每一部分线程执行时,另一部分线程标识为不活跃线程,但是任然占用执行单元。这种情况下一方面因为串行化增加了整体执行时间,另一方面不活跃线程降低了资源利用率。如下图所示(coherent部分表示没有分支的代码):
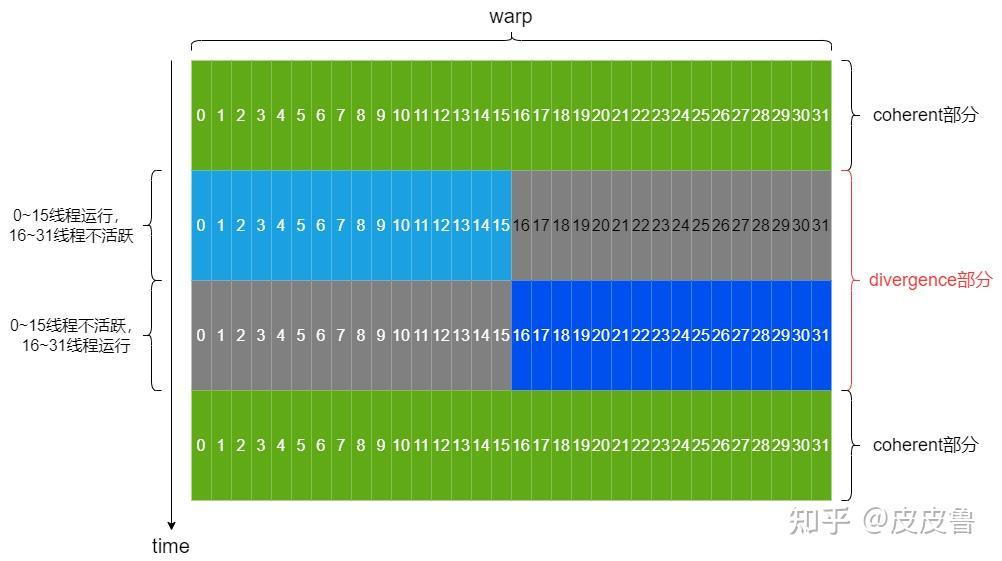
一个Warp一次执行一条公共指令。如果Warp中的线程由于数据依赖而发生条件分支发散,则warp会执行每个需要的分支路径,同时禁用不在该路径执行的线程。因此当一个 Warp中的32个线程都执行相同的执行路径时,Warp的效率是最高的。
编译器可能会进行循环展开,或者会通过分支预测来优化短的if或switch块。在这些情况下,所有Warp都不会发散。程序员还可以使用#pragma unroll指令控制循环展开。如下图所示,每个线程执行不同数量的循环迭代,循环迭代的数量在四和八之间变化。在前四次迭代中,所有线程都是活动的并执行A。在剩余的迭代中,一些线程执行A,而其他线程因为已经完成它们的迭代而不活动。
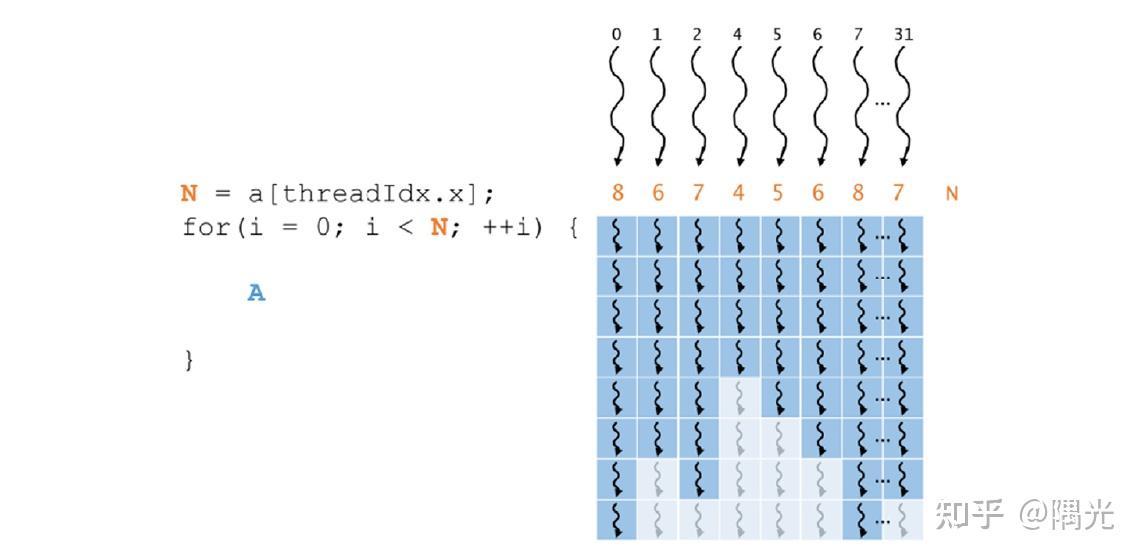
SM占用率
Roofline Model
概念
Roofline Model能帮助我们判断cuda 程序是显存瓶颈(memory bound)还是计算瓶颈(compute bound),以及判断当前资源利用率的情况。
Roofline Model的横坐标是计算强度(computational intensity),单位是FLOP/B,即每读一个Byte所能产生的FLOP数。例如以下base matrix multiply代码:
| |
它的computational intensity是0.25,因为每次2次计算(乘加)需要读8个Byte
Roofline Model是描述一个进程的性能与它所在的硬件的关系,横坐标是计算强度,纵坐标是FLOP/s,如下图所示:
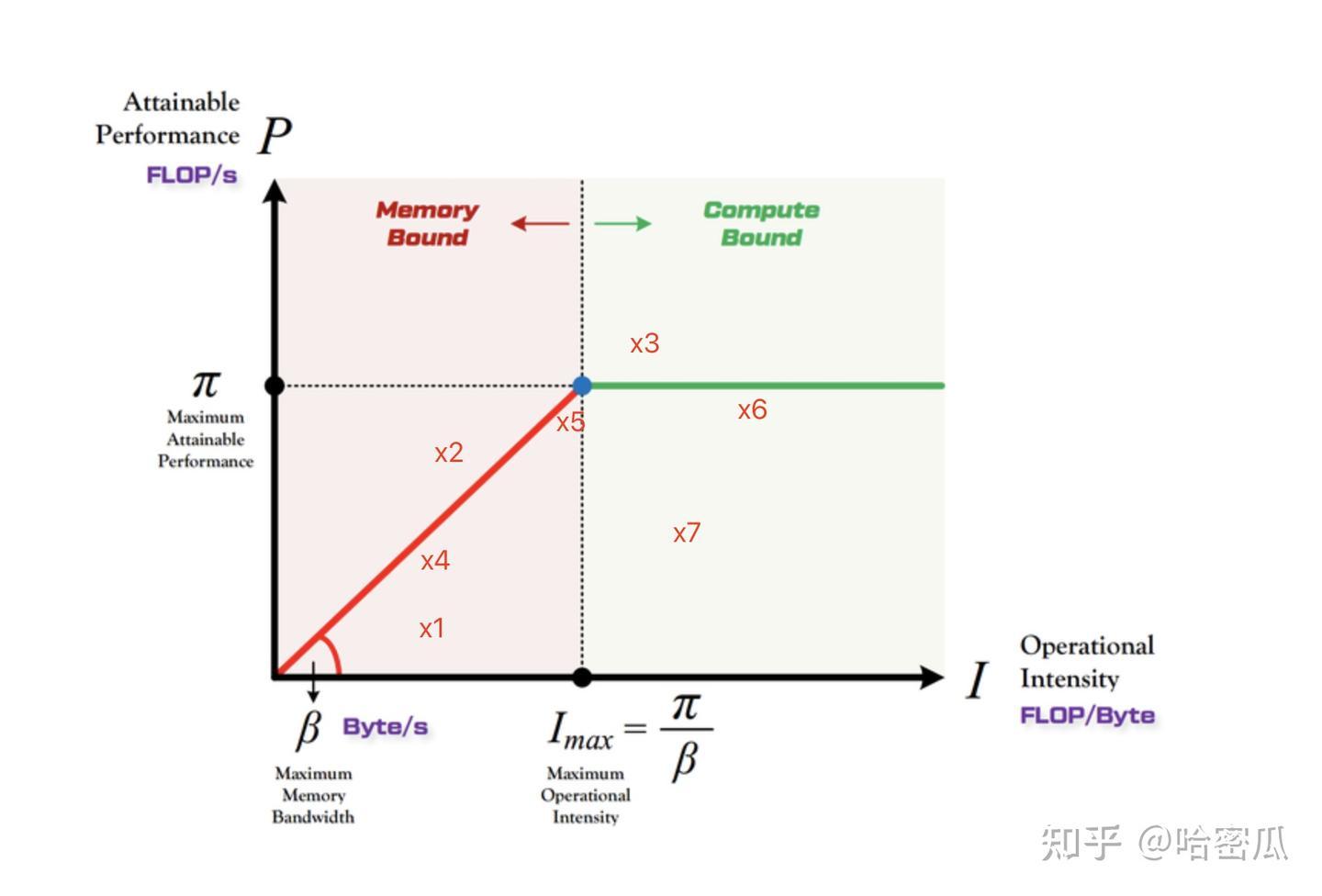
其中 红线(屋檐)和绿线(屋顶) 与具体硬件有关,红线的斜率是内存带宽,不同的硬件斜率不同(带宽越大,斜率越高),越靠近红线说明对带宽资源利用率越高;任何一个点到原点的斜率不可能超过硬件最大带宽 $\beta$
绿线是硬件的计算峰值,高度越靠近绿线,说明对计算资源利用率越高;任何一个点的P值(纵坐标)不可能超过 $\pi$
计算强度D是有可能超过 $I_{max}$ 的,假设某台机器A计算峰值10GFLOPS,内存带宽是10GB/s,那么 $I_{max}=1$ 。假设某个模型疯狂重复计算,对1GB的数据计算5次乘加,计算量 C=10GFLOPs,那么计算强度 $I=10$
为了加深理解,分别举几个示例说明图中的7个点是如何产生的:
假设:机器A计算峰值10GFLOPS,内存带宽是10GB/s,那么 $I_{max}=1$,下面的示例都发生在机器A上:
有一个计算强度高的模型 $D_h$,读取10GB的数据产生100GFLOPs的计算, $I=10$;
另外有一个计算强度低的模型 $D_l$,读取10GB的数据只产生5GFLOPs的计算, $I=0.5$;
$x_2, x_3$ 不可能在现实中出现,正如上面所说,$x_2$ 超过了带宽限制,$x_3$ 超过了硬件计算限制,
举个例:还是对于机器A,计算峰值10GFLOPS,内存带宽是10GB/s,假设有一个计算强度很高的模型,读取1GB数据计算100GFLOPs,计算强度为100,但实际上由于受到计算峰值的限制,P=10GFLOPS,此时计算的斜率为 $\dfrac{10}{100}=0.1<1=\beta$
$x_1, x_4$ 是在计算强度很低的模型中可能出现,以模型 $D_l$ 为例,$x_1$ 出现的原因是由于程序实现问题导致计算性能都很低:例如计算5GFLOPS用了2s(理想情况是0.5s)导致纵坐标P比较低:($I=0.5, P=2.5$),属于工程提升空间很大,不需要增加硬件性能就可大幅度提升性能。
$x_1$ 优化后变为 $x_4$,计算5GFLOPS只用了1s(理想情况是0.5s,但是受限于带宽,1s只能传输10GB数据),已经十分接近屋檐这条线了,但计算强度太低了,优化方向是提升计算强度(只能改变模型,属于模型的计算强度透支)来增加性能,如果算法没办法改进的情况下,那提升性能的方式只能堆更高的带宽了。 $x_4$ 属于内存带宽受限型(模型不动的情况下,无脑增加带宽)。
$x_5$ 属于把硬件资源都用满了(计算和带宽全都吃满),且模型的计算强度也被挖掘得刚刚好。其性能即受限于硬件带宽又受限于计算资源,增加任何一项硬件资源(带宽和计算)都没法提升性能。“刚刚好”的意思是计算强度和硬件刚好匹配,其即使增加了硬件计算和带宽,不改变模型的情况下,也没办法提升性能。它即受限于硬件,又受限于模型。
$x_6$ 也属于把硬件资源都用满了,但模型本身的计算强度还有很大潜力,属于硬件压制了模型。只需要堆计算资源性能就可以提升,模型和带宽都不用动,属于计算受限型。典型示例就是计算强度高的模型 $D_h$ ,计算强度为10,某个实现使得带宽和计算都已经跑满了(每秒读取10GB,计算10GFLOPs,受限于硬件算力和带宽)
$x_7$ 和 $x_1$一样,硬件利用率太低了,需要改进实现,则能成长为 $x_6$ 一样的潜力型选手。例如计算强度高的模型 $D_h$,计算强度为10,但某个实现使得计算没有打满(例如带宽没有打满,10GB数据花了2s,即便计算打满也导致GFLOPS为5GFLOPS,或者计算资源没有吃满,例如10GB数据用了1s传输,2s计算—重复计算、bankconflict之类的导致)
总结:
Roofline model中,越靠近屋檐(红色)或者屋顶(蓝色)的线,说明已经将硬件资源吃得很满,除非修改模型改变计算强度,或者修改硬件,否则很难提升。远离这些线的点,在实现是有提升空间的,离得远,说明实现对硬件的利用率越差。
Roofline model中,在 $I_{max}$ 左边的点,都是内存带宽限制性;在 $I_{max}$ 右边的点,属于计算限制型。如果模型在 $I_{max}$ 的左边且靠近屋檐(红色)线,那么不改模型算法的情况下提升带宽资源能增加性能,如果在 $I_{max}$右边且靠近屋顶(蓝色)的线,那么不改模型算法的情况下提升计算资源能增加性能
不可能有点会处于超过屋檐(红色)或者屋顶(蓝色)的区域
Bank Conflict 与 避免方法
Bank概念
cuda内核在执行的时候往往是以warp为单位去调度和执行,一个warp 32 个线程。所以,为了能够高效访存,shared memory中也对应了分成了32个存储体,这个存储体称之为 bank 。
bank 是CUDA中一个重要概念,是内存的访问时一种划分方式,在GPU中,访问某个地址的内存时,为了减少读写次数,访问地址并不是随机的,而是一次性访问bank内的内存地址,类似于内存对齐一样。一般GPU认为如果一个程序要访问某个内存地址时,其附近的数据也有很大概率会在接下来会被访问到。
(目前N卡都是32个bank),分别对应 warp 中32个线程。
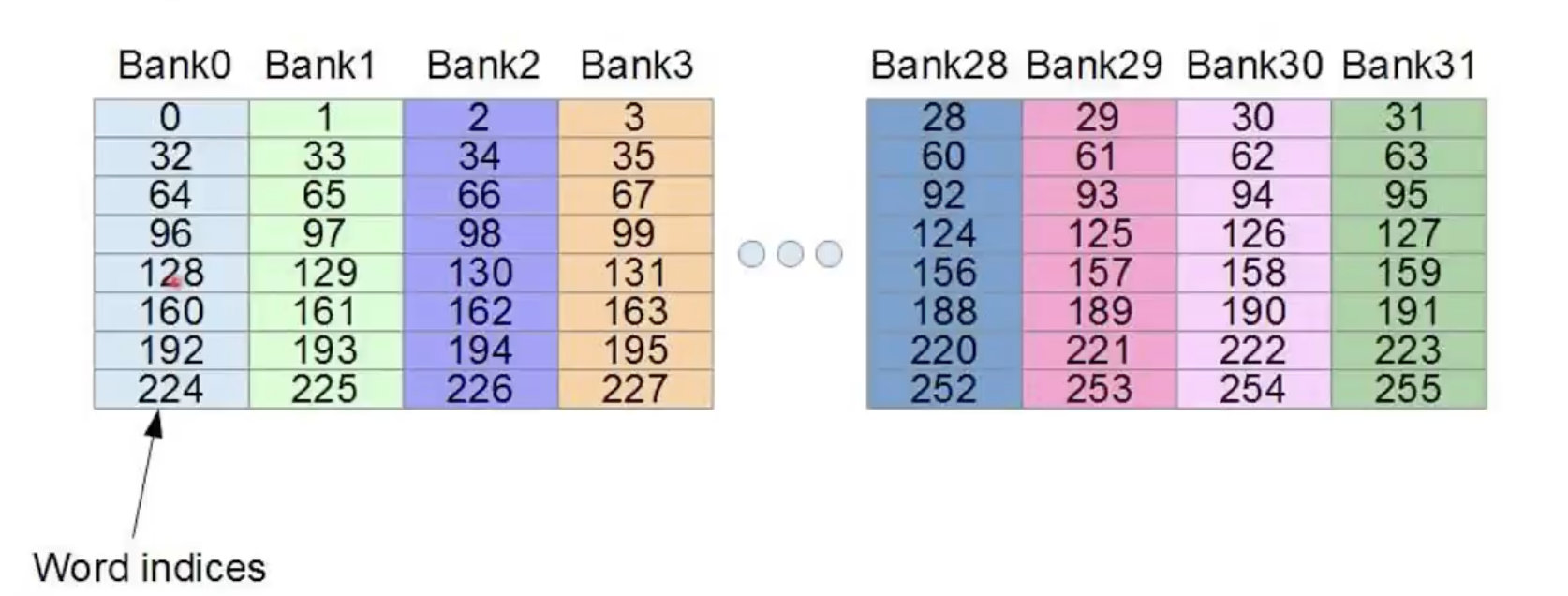
bank的宽度,代表的是一个bank所存储的数据的大小宽度。可以是:
- 4 字节(32bit,单精度浮点数 float32)
- 8 字节(64bit,双精度浮点数 float64)
每 31 个bank,就会进行一次 stride。
比如说 bank 的宽度是4字节,我们在 share mem 中申请了 float A[256] 大小的空间,那么:
| |
Bank Conflict
一个很理想的情况是,32个thread,分别访问share mem中32个不同的bank,没有 bank conflict,一个 memory 周期完成所有的 memory read/write(行优先访问)
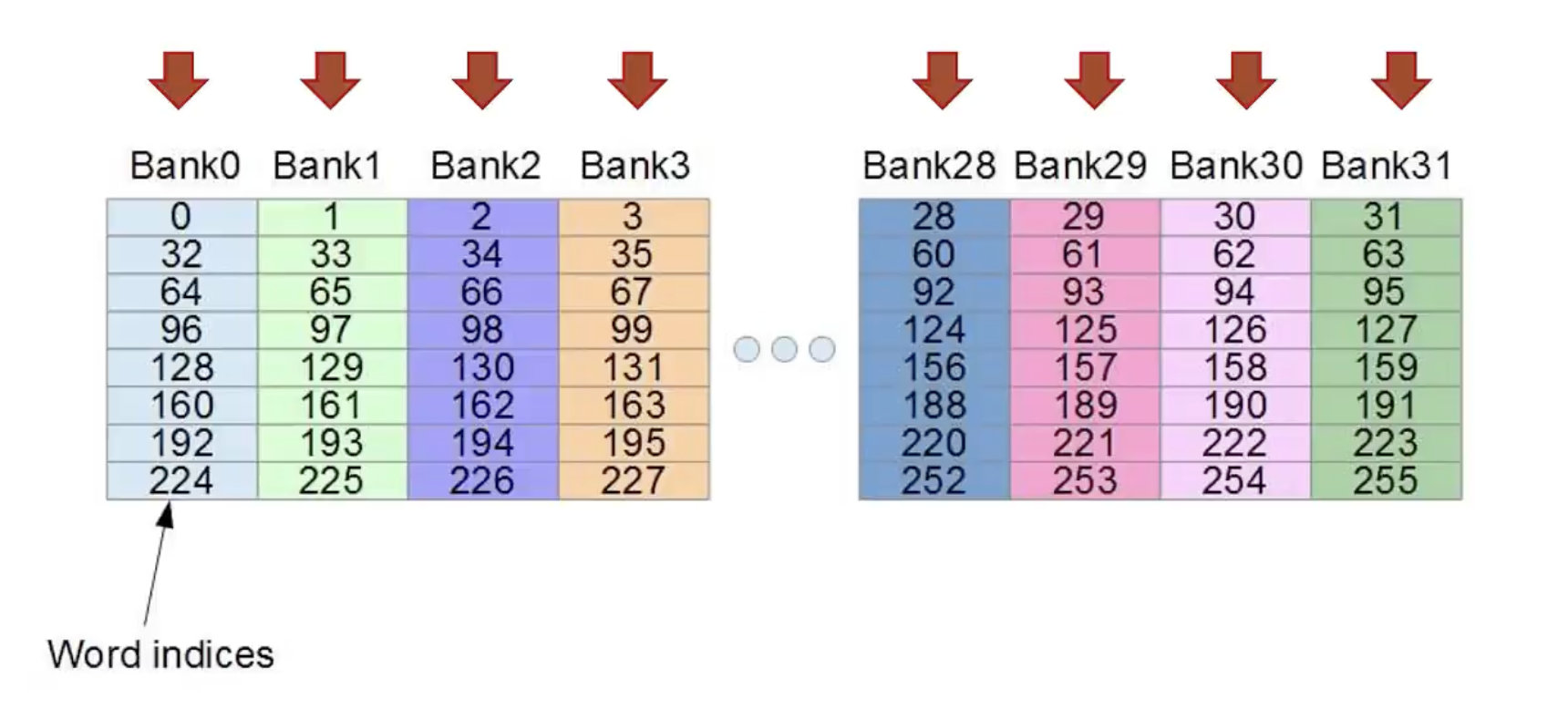
那最不理想的情况就是,32个thread,访问 share mem 中的同一个bank,导致最严重的 bank conflict,需要32个memory 周期才能完成所有的 memory read/write(列优先访问)。如果在block内多个线程访问的地址落入到同一个bank内,那么就会访问同一个bank就会产生bank conflict,这些访问将是变成串行。
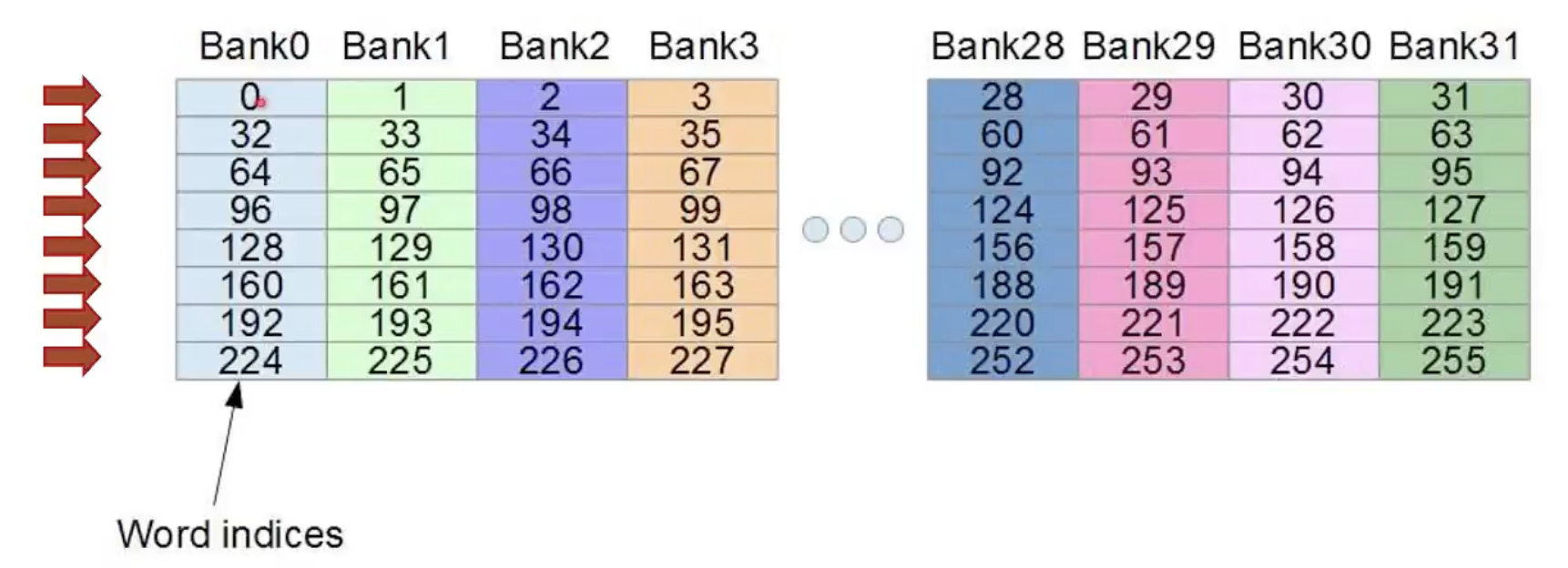
使用 Padding 缓解 Bank Conflict
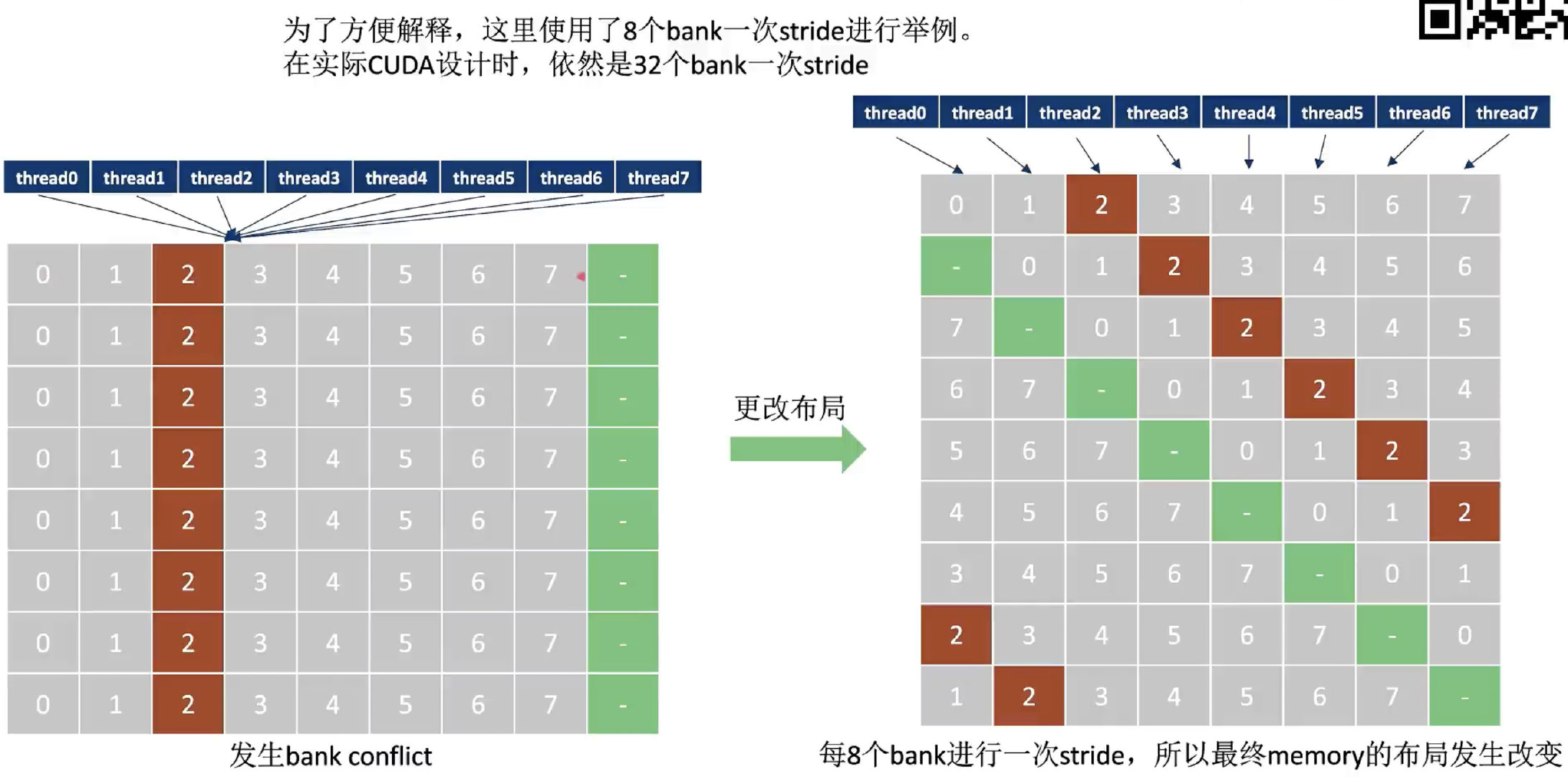
为了方便解释,这里使用了8个bank一次stride进行举例。(实际CUDA设计中依然是32个bank一次stride)
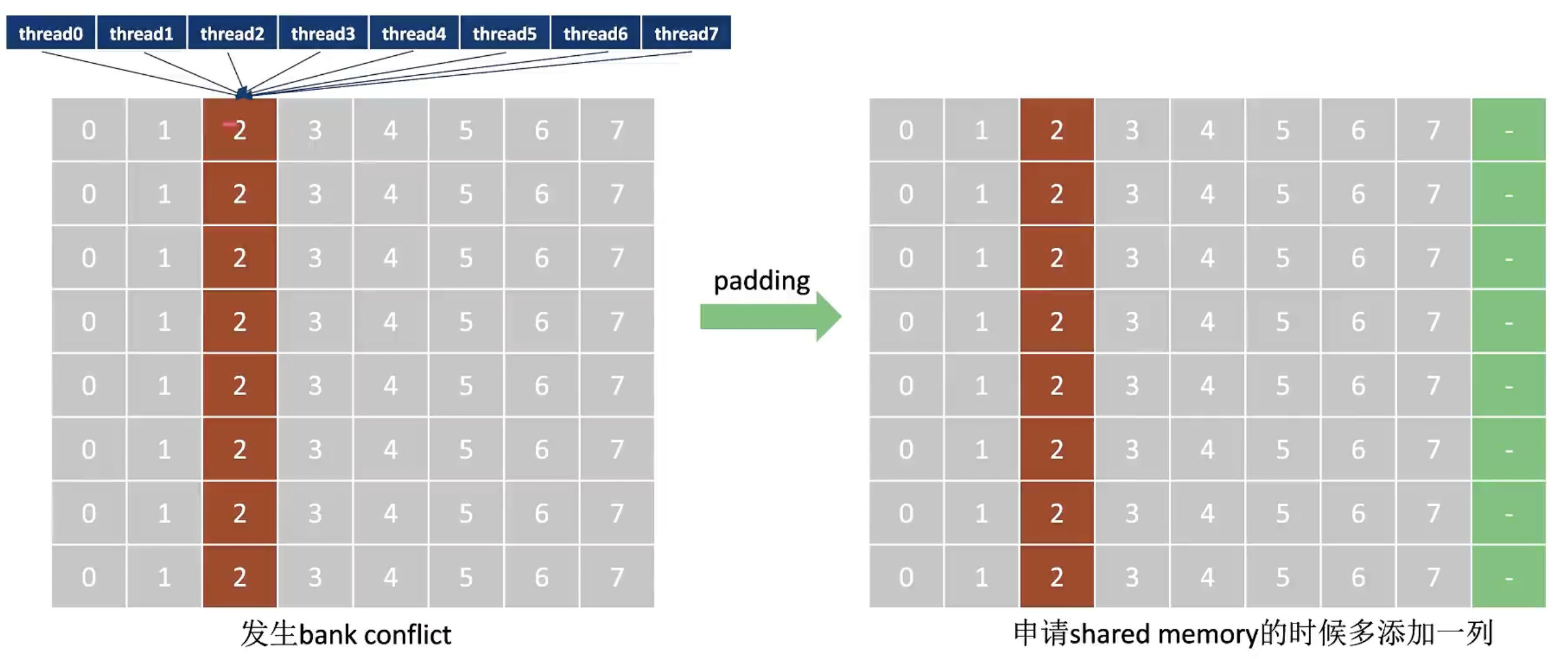
可以在申请share mem时多申请一列(padding),这样就会更改share mem的布局,使得32个线程访问变成串行。
使用 Swizzle 缓解 Bank Conflict
Swizzle通过重新映射内存地址,可以将原本访问相同Bank的线程分散到不同的Bank。Swizzle的核心思想是通过物理地址映射避免Bank Conflict,同时保持逻辑地址不变。在CUTLASS中,Swizzle的实现通过一系列变换对内存布局进行重排。通过行列坐标的异或操作,Swizzle确保每个线程访问不同的Bank,从而实现了Bank Conflict Free的内存访问。
| |
可以用padding和swizzle的示意图来解释下这种物理地址映射的概念:
 ⬆️bank conflict free
⬆️bank conflict free
 ⬆️bank conflict solved by padding
⬆️bank conflict solved by padding
 ⬆️bank conflict solved by swizzle
⬆️bank conflict solved by swizzle
参考文献:
CUDA Stream & CUDA Graph
CUDA Stream
cuda编程里最重要的特性就是异步:CPU提交任务到GPU中异步执行。为了控制异步之间的并发顺序,cuda引入了stream和event的概念。本文尝试分析理解stream和event的含义,充分理解并使用stream、event,是正确、高效利用GPU的必要条件。
只有一个CPU thread的情况
当不考虑GPU的时候,CPU线程就在不断地执行指令。从时间维度上看,就是这样的一条线:

一个CPU thread与一个GPU执行单元
GPU相当于CPU的附属硬件,当我们增加了一个GPU执行单元的时候,由CPU下发任务给GPU,于是从时间维度上看,就出现了两条线:
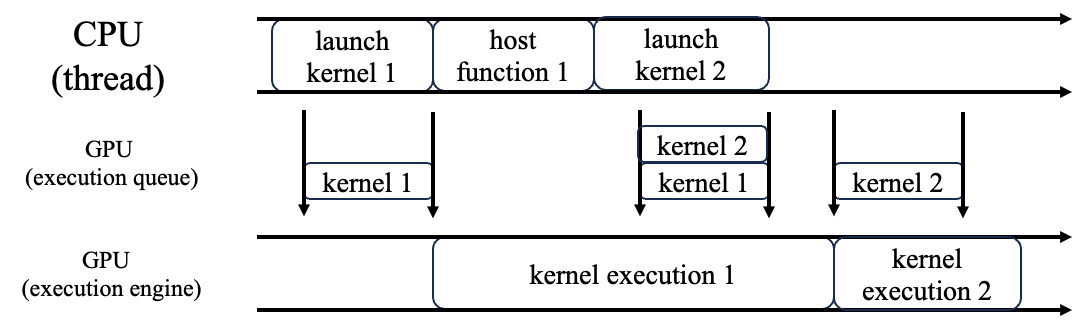
这里在GPU和CPU之间还增加了一个GPU队列。当我们在CPU上调用launch kernel的时候,本质上就是把这个kernel放入到GPU的执行队列里。然后,驱动负责维护这个队列,每当执行引擎(硬件资源)空闲的时候,就执行队列里的kernel。
上图描述了这些关键时间点:
- CPU launch kernel 1,kernel 1入队,此时GPU空闲,于是kernel 1马上开始执行
- CPU调用host function,与GPU无关
- CPU launch kernel 2,kernel 2入队,此时GPU还在执行kernel 1,于是kernel 2继续待在队列里
- GPU执行完kernel 1后,驱动程序发现队列里还有kernel 2,于是开始执行kernel 2(这一步不需要CPU参与)
早期的GPU硬件上只有一个execution engine,因此,不论是哪个进程、哪个线程发起的kernel launch,都在同一个队列里排队。随着GPU的发展,GPU上面开始出现了多个execution engine。
一个CPU thread与2个GPU执行单元
当我们有两个或多个GPU执行单元的时候,我们就可以让GPU kernel之间也并行起来:
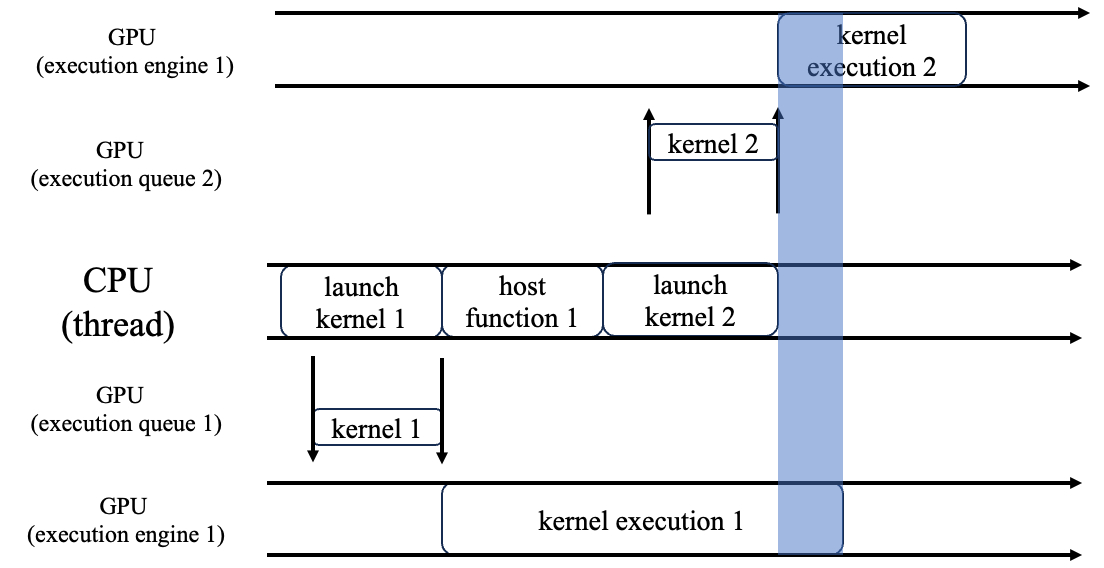
图中蓝色阴影区域就是两个GPU kernel并发执行的时间段。
这里要注意,kernel 1和kernel 2能不能并发执行,需要由用户来决定,硬件不能擅作主张,否则万一kernel 2要读取kernel 1算出来的数据,那并发执行的结果就是错的。
为了给用户提供这种控制权,于是我们就有了stream的概念。一个stream就对应于一个执行队列(加一个执行单元),用户可以自行决定是否把两个kernel分开放在两个队列里。
stream是cuda为上层应用提供的抽象,应用可以创建任意多个stream,下发任意多个kernel。但如果正在执行的kernel数目超过了硬件的execution engine的数量,那么即使当前stream里没有kernel正在执行,下发的kernel也必须在队列里继续等待,直到有硬件资源可以执行。(注意:此时kernel 执行与CPU下发kernel之间依然是异步的)
由此,我们可以总结得到:一个GPU kernel可以执行的必要条件是它在stream的队列首位且存在执行kernel的空闲硬件资源。
创建stream的时候,我们也可以用 cudaStreamCreateWithPriority 为它指定优先级。当多个GPU kernel都可以执行的时候,cuda driver负责调度,优先执行high priority的stream里的kernel。
stream之间的操作:cuda event
我们不仅可以从CPU thread操作stream,也可以在一个stream上面操作另一个stream。当然,stream只是一层抽象,我们依然要借用CPU thread的辅助,来指导“一个stream上面操作另一个stream”。具体的操作也很简单,就是一个stream上面的kernel想等待另一个stream上面的kernel执行结束之后再执行。
为了实现这个目标,我们需要记录另一个stream上面的队列状态,这就是cuda event。让我们来看一个具体的例子:
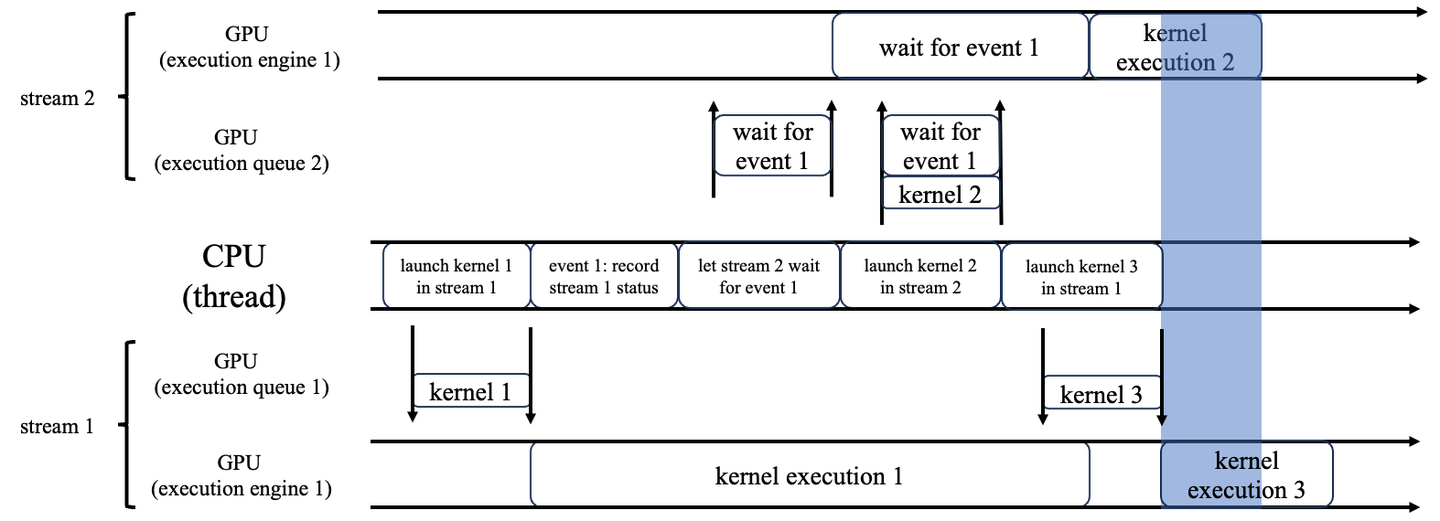
它实现的功能是:
- 在stream 1上面执行kernel 1 和 kernel 3
- 在stream 2上面执行kernel 2,但是必须等到stream 1上面的kernel 1执行结束之后才能开始
为此,我们在stream 1上面launch kernel 1之后,创建一个event来记录当前stream 1的状态(具体来说就是队列里有哪些kernel还没执行),然后把这个event放进stream 2的队列里,让stream 2执行一个想象中的“wait for event 1”的kernel,这个kernel直到kernel 1执行结束之后才离开队列。于是,在这个event之后加入队列的kernel 2,就必须等到kernel 1执行结束之后才能开始了。
这样的好处在于,我们不仅控制了kernel 1和 kernel 2的执行顺序,而且把kernel 2和kernel 3并发执行了,节省了时间(蓝色区域为两个kernel同时执行的时间段)。
CUDA Graph
对GPU进行性能优化时,cudagraph是绕不开的话题。不仅是GPU,大部分的xpu都会提供类似graph mode的优化,相比于每次分别由CPU进行kernel launch的eager mode,graph mode通常都会有较大性能提升,然而也经常容易出现各种各样的奇怪问题。
graph capture期间禁止执行的函数
当一个stream处在graph capture状态时,实际上CPU下发的kernel都没有执行,只是被记录下来了。因此,与GPU kernel执行状态相关的函数都不能使用,例如:
- 对stream进行同步(cudaStreamSynchronize)
- 隐含stream同步的操作(对context进行同步、对device进行同步,都会强制内部包含的全部stream进行同步,如果其中有stream处在graph capture状态,就会报错)
- 隐含stream同步的操作,如当前graph capture的stream是blocking stream,则涉及null stream的操作都不可用,例如cudaMalloc
- 对stream上面record的event进行的状态查询、同步操作
- 另外断点调试在这期间也是用不了的
更详细的限制可以看官方文档:https://docs.pytorch.org/docs/stable/notes/cuda.html
| |
其中,因为PyTorch的功能的一些限制,我们的代码发生了变化:PyTorch里的 a.to("cpu"),会强制同步使得host to device完成同步,即使加上 non_blocking=True 也无法改变。这与cudagraph不兼容。为了解决这个问题,我们手动调用了 cudaMemcpyAsync 函数,实现了异步拷贝到CPU的功能。(如果要PyTorch里直接实现这一功能,需要async CPU的支持。)
执行以上代码,捕获的计算图为:
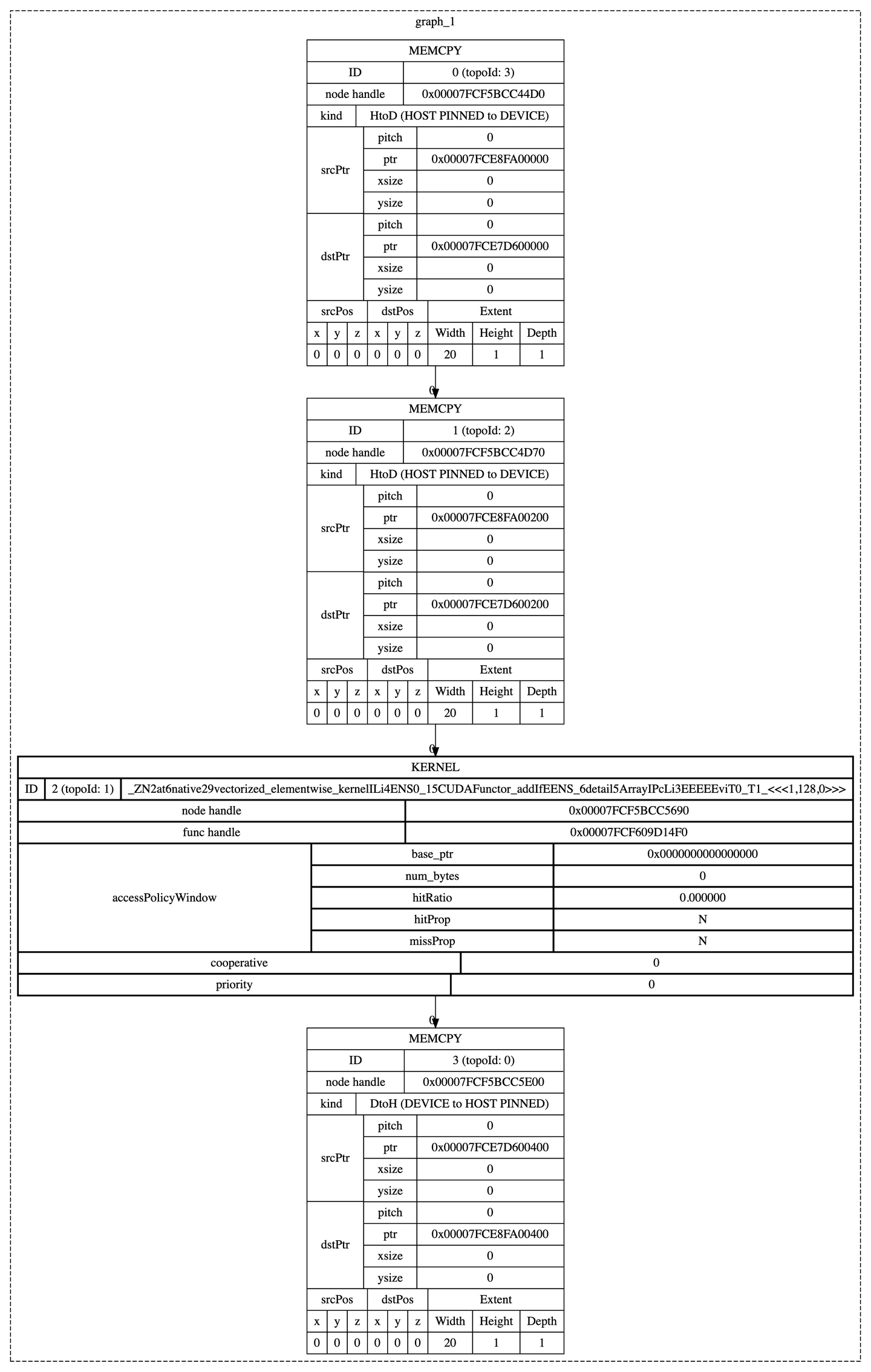
PTX & SASS & libdevice
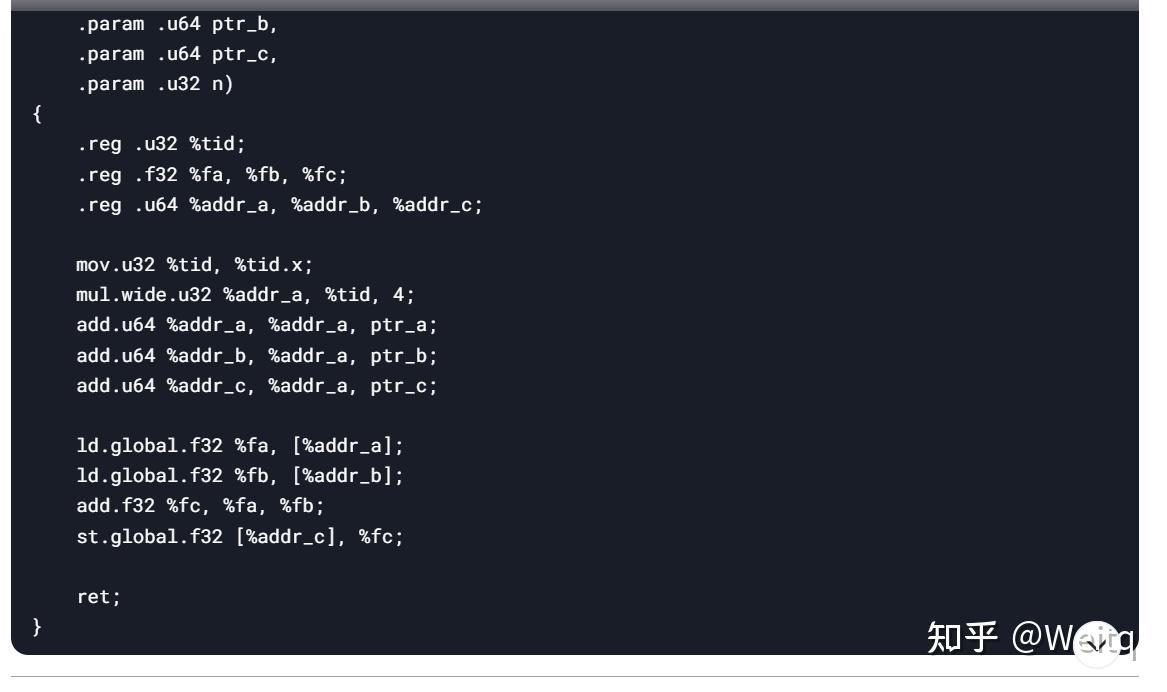
PTX(Parallel Thread Execution)
- PTX 是NVIDIA设计的中间表示(IR),类似于GPU的汇编语言,但独立于具体硬件架构。
- PTX代码由NVCC生成,可以被NVIDIA的驱动程序进一步编译为特定GPU架构的机器代码(SASS)。
- PTX代码是文本格式,便于阅读和调试。
示例:
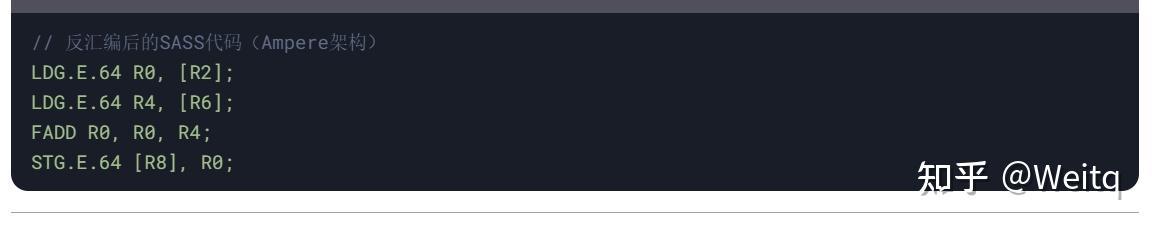
SASS (Streaming ASSembly)
- SASS 是NVIDIA GPU的机器代码,直接由GPU硬件执行。
- SASS是二进制格式,特定于具体的GPU架构(如Ampere、Turing)。
- SASS代码通常通过反汇编工具(如cuobjdump)查看。
示例:
libdevice
- libdevice 是NVIDIA提供的一个数学函数库,包含高度优化的设备端数学函数(如sin、exp、log等)
- 这些函数以PTX或SASS形式提供,可以直接链接到CUDA程序中。
- libdevice库的文件通常命名为libdevice.*.bc(LLVM bitcode格式)。
在CUDA程序中,调用标准数学函数(如sin、cos)时,NVCC会自动链接libdevice库。开发者也可以通过 -lcudadevrt显式链接libdevice。
转换流程
以下是CUDA代码从高级语言到最终机器代码的转换流程:
- CUDA C/C++ → PTX
- NVCC将CUDA设备代码编译为PTX。
- 示例命令:
| |
- PTX → SASS
- NVIDIA的驱动程序将PTX代码编译为特定GPU架构的SASS代码。
- 这一步在运行时或安装时完成。
CUTLASS & CUTE
CUTLASS
CUTLASS(CUDA Template for Linear Algebra Subroutines)是指NVIDIA开源的一个高性能CUDA模板库,用于实现高效的线性代数计算,里面提供了包括访存,计算,流水线编排等多个level的模板。用户通过CUTLASS模板组装以及特化,可以搭建出自己需要的高性能CUDA Kernel。
核心思想是模块化和通用化。它不像传统的库(如 cuBLAS)那样提供预编译好的函数,而是提供了一套模板,让你能够根据自己的需求组合出最优化的计算内核。这使得开发者可以针对特定的矩阵尺寸、数据类型(如 FP16、FP32、INT8 等)和计算模式,生成定制化的、性能极高的内核,而无需从头手写汇编代码。
CUTE
CUTE 是一个更底层的、用于描述和操作 GPU 上多维数据布局 (tensor layout) 的 C++ 库。 它不是一个完整的应用库,而是一套强大的、用于构建其他高级库(如 CUTLASS)的工具集。
CUTE 的核心思想是提供一套数学化的、声明式的张量抽象,让开发者可以精确地描述数据在内存中的排布方式。它解决了以下核心问题:
张量布局 (Tensor Layout): 如何描述一个多维数组(张量)在内存中的存储方式,例如行主序、列主序,或者更复杂的分块和交错布局。
张量视图 (Tensor View): 如何在不移动数据的情况下,创建张量的子视图,并对子视图进行操作。
跨步操作 (Striding): 如何高效地计算多维数组中元素的地址。
你可以把 CUTE 理解为一个“张量布局的 DSL (Domain-Specific Language)”。 它提供了一种简洁的方式来表达复杂的数据访问模式,这对于编写 GPU 上的高性能通用代码至关重要。CUTLASS 内部就广泛使用了 CUTE 来管理和操作其张量数据,从而实现了其灵活性和性能。
Global Memory的访存合并
参考文献:
当前的GPU架构允许通过编译选项来控制是否启用一级缓存。当一级缓存被禁用时,对全局内存的加载请求将直接进入二级缓存;如果二级缓存未命中,将由DRAM完成请求。核函数从全局内存DRAM中读取数据有两种粒度, 使用一级缓存时,每次按照128字节进行缓存;不使用一级缓存时,每次按照32字节进行缓存。
| |
传输延迟
在host端和device端之间存在latency,数据通过PCI-E总线从CPU传输给GPU,我们必须避免频繁的host、device间数据传输,即使是最新的PCIE 3.0 x16接口,其双向带宽也只有32GB/s
在device内部也存在latency,即数据从gpu的存储器到multi-processor(SM)的传输。
访问一次全局内存,将耗费400~600个cycle,成本是非常高的,所以必须谨慎对待全局内存的访问
我们把一次内存请求——也就是从内核函数发起请求,到硬件响应返回数据这个过程称为一个内存事务(加载和存储都行)。
合并访存
数据从全局内存到SM(stream-multiprocessor)的传输,会进行cache,如果cache命中了,下一次的访问的耗时将大大减少。
基本逻辑是: 首先判断这个 Kernel 的数据流路径,是否使用了 L1 cache,由此得出当前内存访问的最小粒度: 32 Bytes / 128 Bytes. 分析原始数据存储的结构,结合访存粒度,分析数据访问是否内存对齐,数据是否能合并访问。
对于L1 cache,每次按照128字节进行缓存;对于L2 cache,每次按照32字节进行缓存。
意思是表示线程束中每个线程以一个字节(1*32=32)、16位(2*32=64)、32位(4*32=128)为单位读取数据。前提是,访问必须连续,并且访问的地址是以32字节对齐。
例子,假设每个thread读取一个float变量,那么一个warp(32个thread)将会执行32*4=128字节的合并访存指令,通过一次访存操作完成所有thread的读取请求。
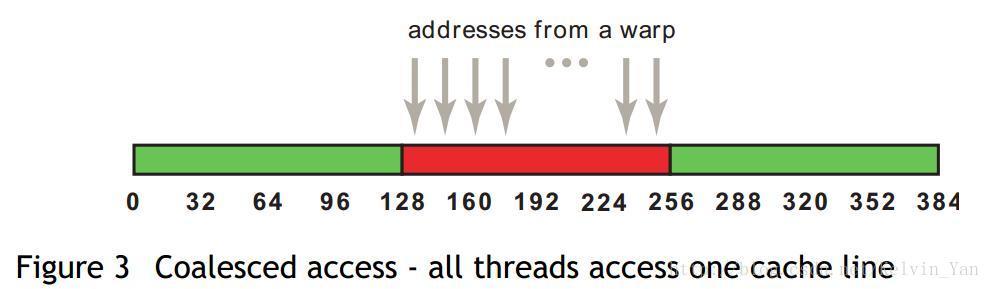
对于L2 cache,合并访存的字节减少为32字节,那么L2 cache相对L1 cache的好处就是:
在非对齐访问、分散访问(非连续访问)的情况下,提高吞吐量(cache的带宽利用率)
对齐/非对齐访问
当一个内存事务的首个访问地址是缓存粒度(32或128字节)的偶数倍的时候:比如二级缓存32字节的偶数倍64,128字节的偶数倍256的时候,这个时候被称为对齐内存访问,非对齐访问就是除上述的其他情况,非对齐的内存访问会造成带宽浪费。
合并/非合并访问
当一个线程束内的线程访问的内存都在一个内存块(缓存粒度)里的时候,就会出现合并访问。
对齐合并访问的状态是理想化的,也是最高速的访问方式,当线程束内的所有线程访问的数据在一个内存块,并且数据是从内存块的首地址开始被需要的,那么对齐合并访问出现了。为了最大化全局内存访问的理想状态,尽量将线程束访问内存组织成对齐合并的方式,这样的效率是最高的。
一个线程束加载数据,使用一级缓存,并且这个事务所请求的所有数据在一个128字节的对齐的地址段上(对齐的地址段是我自己发明的名字,就是首地址是粒度的偶数倍,那么上面这句话的意思是,所有请求的数据在某个首地址是粒度偶数倍的后128个字节里),具体形式如下图,这里请求的数据是连续的,其实可以不连续,但是不要越界就好。
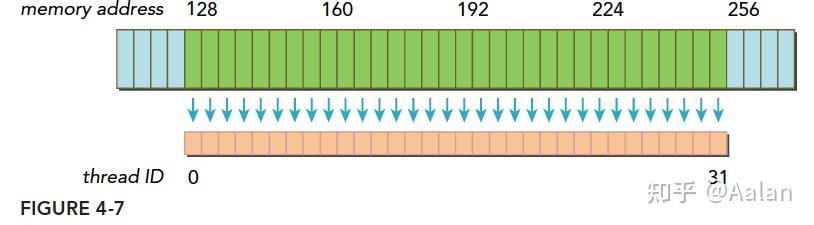
如果一个事务加载的数据分布在不一个对齐的地址段上,就会有以下两种情况:
- 连续的,但是不在一个对齐的段上,比如,请求访问的数据分布在内存地址 1-128,那么0-127和128-255这两段数据要传递两次到SM
- 不连续的,也不在一个对齐的段上,比如,请求访问的数据分布在内存地址0-63和128-191上,明显这也需要两次加载。
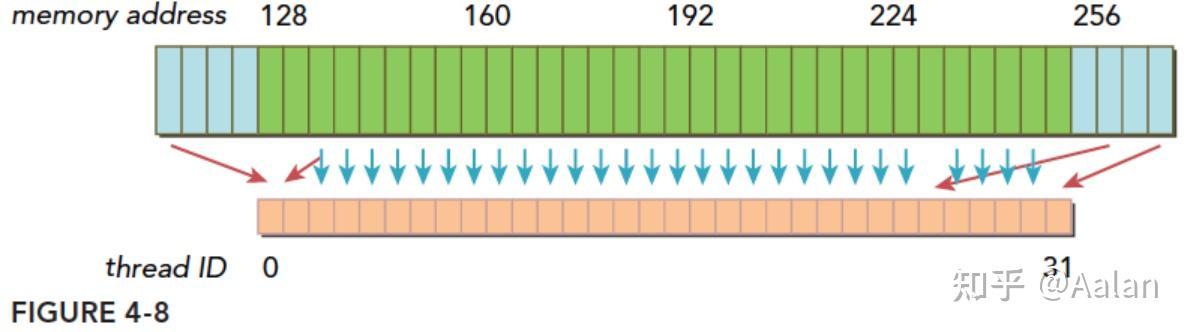
数据分散开了,thread0的请求在128之前,后面还有请求在256之后,所以需要三个内存事务,而利用率,也就是从主存取回来的数据被使用到的比例,只有 128/(3*128) 的比例。这个比例低会造成带宽的浪费,最极端的表现,就是如果每个线程的请求都在不同的段,也就是一个128字节的事务只有1个字节是有用的,那么利用率只有 1/128.
实例——写一个 内存访问非对齐的kernel
| |
这里用一个 sum kernel 进行举例,float*A, float*, float*C 都是从 glb mem 读取数据,每个 thread 会去load 一个数据进行处理。通过 offset 可以改变 thead load 数据的偏移地址,从而来试验不同 cache 粒度的 合并访问现象。
可以发现禁用 L1 cache 前后,另外 offset = 0 和 offset = 32 得到上述理论结果。
常用的profile工具和方法
- Nsight System
- Nsight Compute
- compute-sanitizer
- vllm core dump
- perfetto 分析 torch profile 文件
 支付宝
支付宝 微信
微信